
DataFrame merge() SQL과 비슷한 부분이 많음.
- merge함수는 key를 기준으로 두 데이터 프레임의 공통 column 혹은 인덱스를 기준으로 두 개의 테이블을 합친다.
- 이때 기준이 되는 column, row의 데이터를 key라고 한다.
df1 = pd.DataFrame({
'고객번호': [1001, 1002, 1003, 1004, 1005, 1006, 1007],
'이름': ['둘리', '도우너', '또치', '길동', '희동', '마이콜', '영희']
}, columns=['고객번호', '이름'])
df1
고객번호 이름
| 0 | 1001 | 둘리 |
| 1 | 1002 | 도우너 |
| 2 | 1003 | 또치 |
| 3 | 1004 | 길동 |
| 4 | 1005 | 희동 |
| 5 | 1006 | 마이콜 |
| 6 | 1007 | 영희 |
df2 = pd.DataFrame({
'고객번호' : [1001,1001,1005,1006,1008,1001], # 고객번호가 key인데 중복되는 값이 있음.
'금액' : [10000,20000,15000,5000,100000,30000]
},columns = ['고객번호','금액'])
df2
고객번호 금액
| 0 | 1001 | 10000 |
| 1 | 1001 | 20000 |
| 2 | 1005 | 15000 |
| 3 | 1006 | 5000 |
| 4 | 1008 | 100000 |
| 5 | 1001 | 30000 |
pd.merge(df1,df2) # innder join= 공통 column인 고객번호 column을 기준으로 데이터를 찾아서 합친다.
# 양쪽 DataFrame에 모두 키가 존재하는 데이터만 보여주는 inner join방식을 사용한다.
고객번호 이름 금액
| 0 | 1001 | 둘리 | 10000 |
| 1 | 1001 | 둘리 | 20000 |
| 2 | 1001 | 둘리 | 30000 |
| 3 | 1005 | 희동 | 15000 |
| 4 | 1006 | 마이콜 | 5000 |
merge 추가 속성
- how = ‘outer’ => outer join 방식은 키 값이 한쪽에만 있어도 데이터를 보여준다.
- how = ‘left’ => 첫 번째 인수 기준으로 DataFrame의 키 값을 모두 보여준다.
- how = ‘right’ => 두번째 인수 기준으로 DataFrame의 키 값을 모두 보여준다.
pd.merge(df1,df2,how='outer')
고객번호 이름 금액
| 0 | 1001 | 둘리 | 10000.0 |
| 1 | 1001 | 둘리 | 20000.0 |
| 2 | 1001 | 둘리 | 30000.0 |
| 3 | 1002 | 도우너 | NaN |
| 4 | 1003 | 또치 | NaN |
| 5 | 1004 | 길동 | NaN |
| 6 | 1005 | 희동 | 15000.0 |
| 7 | 1006 | 마이콜 | 5000.0 |
| 8 | 1007 | 영희 | NaN |
| 9 | 1008 | NaN | 100000.0 |
pd.merge(df1,df2,how='left')
고객번호 이름 금액
| 0 | 1001 | 둘리 | 10000.0 |
| 1 | 1001 | 둘리 | 20000.0 |
| 2 | 1001 | 둘리 | 30000.0 |
| 3 | 1002 | 도우너 | NaN |
| 4 | 1003 | 또치 | NaN |
| 5 | 1004 | 길동 | NaN |
| 6 | 1005 | 희동 | 15000.0 |
| 7 | 1006 | 마이콜 | 5000.0 |
| 8 | 1007 | 영희 | NaN |
pd.merge(df1,df2,how='right')
고객번호 이름 금액
| 0 | 1001 | 둘리 | 10000 |
| 1 | 1001 | 둘리 | 20000 |
| 2 | 1005 | 희동 | 15000 |
| 3 | 1006 | 마이콜 | 5000 |
| 4 | 1008 | NaN | 100000 |
| 5 | 1001 | 둘리 | 30000 |
df2.value_counts()
df2.count()

df1 = pd.DataFrame({
'품종' : ['setosa','setosa','virginica','virginica'],
'꽃잎길이' : [1.4,1.3,1.5,1.3]},
columns = ['품종','꽃잎길이'])
df1
품종 꽃잎길이
| 0 | setosa | 1.4 |
| 1 | setosa | 1.3 |
| 2 | virginica | 1.5 |
| 3 | virginica | 1.3 |
df2 = pd.DataFrame({
'품종' : ['setosa','virginica','virginica','versicolor'],
'꽃잎너비' : [0.4,0.3,0.5,0.3]},
columns = ['품종','꽃잎너비'])
df2
품종 꽃잎너비
| 0 | setosa | 0.4 |
| 1 | virginica | 0.3 |
| 2 | virginica | 0.5 |
| 3 | versicolor | 0.3 |
pd.merge(df1,df2)
품종 꽃잎길이 꽃잎너비
| 0 | setosa | 1.4 | 0.4 |
| 1 | setosa | 1.3 | 0.4 |
| 2 | virginica | 1.5 | 0.3 |
| 3 | virginica | 1.5 | 0.5 |
| 4 | virginica | 1.3 | 0.3 |
| 5 | virginica | 1.3 | 0.5 |
DataFrame 시계열 자료 다루기
- 인덱스가 날짜 혹은 시간인 데이터를 말한다.
- Datetimeindex 인덱스는 아래 두 보조 함수를 사용하여 생성한다
- pd.to_datetime 함수
- pd.date_range 함수
# pd.to datetime 함수를 쓰면 날짜/ 시간을 나타내는 문자열을 자동으로 datetime 자료형으로 바꾼 후 DatetimeIndex 자료형 인덱스를 생성한다.
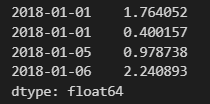
date_str = ['2018, 1, 1','2018, 1, 1','2018, 1, 5', '2018, 1, 6']
idx = pd.to_datetime(date_str)
idx

#만들어진 시계열 인덱스를 사용하여 Series나 DataFrame을 생성한다.
np.random.seed(0)
s = pd.Series(np.random.randn(4),index = idx)
s
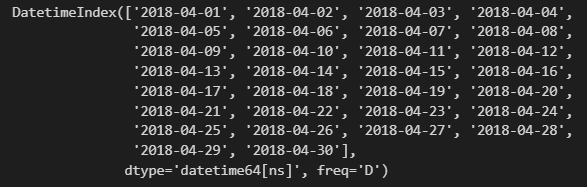
# date_range 함수로 모든 날짜/ 시간을 일일이 입력할 필요 없이 시작일과 종료일을 입력하여 범위 내의 인덱스를 생성해준다.
pd.date_range('2018-4-1','2018-4-30')
# 또는 시작일과 기간을 입력하여 범위 내의 인덱스를 생성해준다.
pd.date_range(start = '2018-4-1',periods=30)

freq 인수로 특정한 날짜만 생성되도록 한다
- s: 초
- T: 분
- H: 시간
- D: 일(day)
- B: 주말이 아닌 평일
- W: 주(일요일)
- W-MON: 주(월요일)
- M: 각 달(month)의 마지막 날
- MS: 각 달의 첫날
- BM: 주말이 아닌 평일 중에서 각 달의 마지막 날
- BMS: 주말이 아닌 평일 중에서 각 달의 첫날
- WOM-2 THU: 각 달의 두 번째 목요일
- Q-JAN: 각 분기의 첫달의 마지막 날
- Q-DEC: 각 분기의 마지막 달의 마지막 날
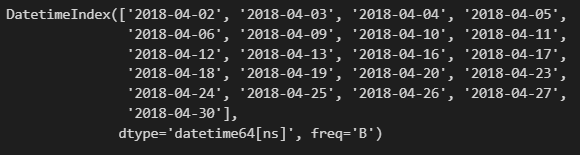
pd.date_range('2018-4-1','2018-4-30',freq ='B')
pd.date_range('2018-4-1','2018-4-30',freq ='W')

pd.date_range('2018-4-1','2018-4-30',freq ='W-Mon')

pd.date_range('2018-4-1','2018-4-30',freq ='MS')

추가적인 속성 shift
- 시계열 데이터의 인덱스는 시간이나 날짜를 나타내기 때문에 날짜 이동 등의 다양한 연산이 가능하다
- shift연산을 사용하여 인덱스는 그대로 두고 데이터만 이동하는 것도 가능하다
np.random.seed(0)
ts = pd.Series(np.random.randn(4),index = pd.date_range('2018-1-1',periods=4,freq='M'))
ts

ts.shift(1) # 인덱스는 변하지 않고 하루씩 데이터가 밀린것을 볼 수 있다. , 첫값은 알 수 없으니 NaN으로 표기된다.

ts.shift(-1) # 마지막 값은 알 수 없으니 NaN으로 표기된다.
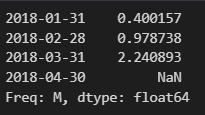
ts.shift(1,freq = "M") # freq = '속성값' 을 사용하여 값은 그대로 두고, 인덱스만 shift하는 것이 가능하다.

ts.shift(1, freq = 'W') # 동일하게 index가 shift된 예제.

추가적인 속성 periods 와 메서드
- periods를 사용하여 값 개수 지정 가능
- year, day, month를 통해 날짜를 개별적으로 추출할 수 있다.
- weekday를 사용하여 요일에 대한 정보를 알아낼 수 있다.
s = pd.Series(pd.date_range('2020-12-25',periods=100, freq = 'D')) # 100개의 날짜를 day 기준으로 연속생성.
s.head(5)

s.dt.year.head(5) # month day도 존재함.
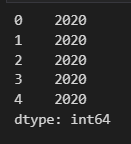
s.dt.weekday.head(5) # 요일에 대해 숫자로 인코딩한 결과를 알아낼 수 있다.

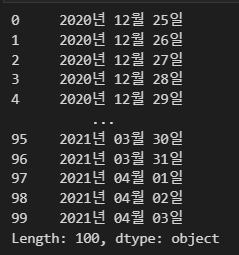
s.dt.strftime('%Y년 %m월 %d일') #대소문자 구분이 있어서 y로 하면 20년만 출력되기도함.
DataFrame 그룹 연산 메서드
- 묶음 별로 처리해서 값을 얻을 수 있도록 처리해 주는 메서드
- unique 한 애들을 가져오고 그놈들의 row들에 대해 뭔가를 별도로 처리하기 위해 사용
np.random.seed(0)
df2 = pd.DataFrame({
'key1' : ['A','A','B','B','A'],
'key2' : ['one','two','one','two','one'],
'data1': [1,2,3,4,5],
'data2': [10,20,30,40,50]
})
df2
key1 key2 data1 data2
| 0 | A | one | 1 | 10 |
| 1 | A | two | 2 | 20 |
| 2 | B | one | 3 | 30 |
| 3 | B | two | 4 | 40 |
| 4 | A | one | 5 | 50 |
#groupby 명령을 사용하여 그룹 A와 그룹 B로 구분한 그룹 데이터를 만든다.
groups = df2.groupby(df2.key1) # key1에 대해 그룹처리해라
groups
# GroubBy 클래스 객체에는 각 그룹 데이터의 인덱스를 저장한 groups 속성이 존재한다
groups.groups

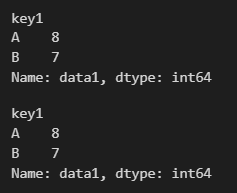
groups.sum() # A그룹과 B그룹 데이터의 합계를 구하기 위한 그룹연산 가능
date1 date2
| key1 | ||
| A | 8 | 80 |
| B | 7 | 70 |
# 할당하지 않고도 사용가능하다.
#column data1에 대해서만 key1에 대해 그룹을 하고, 그룹연산하는 코드다
df2.data1.groupby(df2.key1).sum()
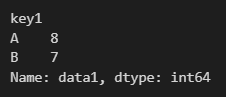
print(df2.groupby(df2.key1)['data1'].sum()) # 데이터 그룹으로 나눈 GroupBy 클래스 객체에서 합쳐도 되고,
df2.groupby(df2.key1).sum()['data1']#또는 그룹분석한 결과에서 data1만 뽑아도 된다
복합키 값에 따른 data1의 합계를 구하자
- 분석하고자 하는 키가 복수이면 리스트를 사용한다.
df2.data1.groupby([df2.key1, df2.key2]).sum() # 각각에 대한 sum결과를 얻을 수 있다.

그룹분석 기능을 사용하면 위의 인구 데이터로부터 지역별 합계를 구할 수도 있다.
data = {
"도시": ["서울", "서울", "서울", "부산", "부산", "부산", "인천", "인천"],
"연도": ["2015", "2010", "2005", "2015", "2010", "2005", "2015", "2010"],
"인구": [9904312, 9631482, 9762546, 3448737, 3393191, 3512547, 2890451, 263203],
"지역": ["수도권", "수도권", "수도권", "경상권", "경상권", "경상권", "수도권", "수도권"]
}
columns = ["도시", "연도", "인구", "지역"]
df1 = pd.DataFrame(data, columns=columns)
df1
도시 연도 인구 지역
| 0 | 서울 | 2015 | 9904312 | 수도권 |
| 1 | 서울 | 2010 | 9631482 | 수도권 |
| 2 | 서울 | 2005 | 9762546 | 수도권 |
| 3 | 부산 | 2015 | 3448737 | 경상권 |
| 4 | 부산 | 2010 | 3393191 | 경상권 |
| 5 | 부산 | 2005 | 3512547 | 경상권 |
| 6 | 인천 | 2015 | 2890451 | 수도권 |
| 7 | 인천 | 2010 | 263203 | 수도권 |
df1['인구'].groupby([df1['지역'],df1['연도']]).sum().unstack('연도')
연도 2005 2010 2015
| 지역 | |||
| 경상권 | 3512547 | 3393191 | 3448737 |
| 수도권 | 9762546 | 9894685 | 12794763 |
unique()로 가진 값들이 무엇인지 볼 수 있다.
titanic['survived'].unique()

Pandas describe()
- 데이터셋에 describe() 메서드를 사용해 보면 통계에 대한 요약 정보를 한눈에 파악할 수 있는 DataFrame의 결과를 얻을 수 있다.
import pandas as pd
import seaborn as sns
penguins = sns.load_dataset('penguins')
penguins.describe()
bill_length_mm bill_depth_mm flipper_length_mm body_mass_g
| count | 342.000000 | 342.000000 | 342.000000 | 342.000000 |
| mean | 43.921930 | 17.151170 | 200.915205 | 4201.754386 |
| std | 5.459584 | 1.974793 | 14.061714 | 801.954536 |
| min | 32.100000 | 13.100000 | 172.000000 | 2700.000000 |
| 25% | 39.225000 | 15.600000 | 190.000000 | 3550.000000 |
| 50% | 44.450000 | 17.300000 | 197.000000 | 4050.000000 |
| 75% | 48.500000 | 18.700000 | 213.000000 | 4750.000000 |
| max | 59.600000 | 21.500000 | 231.000000 | 6300.000000 |
pandas 연습문제들
import seaborn as sns
import pandas as pd
titanic = sns.load_dataset('titanic')
# alive column을 booleantype으로 변경
def change_boolean(value):
if value == 'yes':
return True
else: return False
titanic['alive'] = titanic['alive'].apply(change_boolean)
titanic['alive'].head(10)
#titanic['alive'] = titanic['alive'].apply(lambda k : True if k == 'yes' else False)
#titanic['alive']

# age 20 이상이고 여자인 놈들은 True 아니면 False로 저장해라
import pandas as pd
import seaborn as sns
titanic = sns.load_dataset('titanic')
titanic = titanic[titanic['age'].notnull()]
titanic['adult_female'] = titanic.apply(lambda x : True if x.age>=20 and x.sex =='female' else False, axis = 1)
titanic['adult_female']
#선생님 코드
#titanic['adult_female'] = (titanic['sex'] == 'female') & (titanic['age']>= 20)
#titanic

# 위에 놈을 csv로 저장하고 불러와봐라는 문제였음.
titanic.to_csv('titanic_age.csv',index = False)
#titanic.read_csv('titanic_age.csv').head()
import seaborn as sns
titanic = sns.load_dataset('titanic')
titanic.groupby('pclass').sum()['survived']/titanic['pclass'].value_counts()

# 선생님 코드titanic[['pclass','survived']].groupby('pclass').mean()
survived
| pclass | |
| 1 | 0.629630 |
| 2 | 0.472826 |
| 3 | 0.242363 |
group = titanic[['sex','survived']].groupby('sex')
group.mean()
survived
| sex | |
| female | 0.742038 |
| male | 0.188908 |
# 펭귄에 NaN값의 개수를 구하고 싶을때
import seaborn as sns
penguins = sns.load_dataset('penguins')
len(penguins)- penguins.count()
# 또는
penguins.isna().sum() #도 가능하다.

# NaN값을 가지는 모든 값들을 출력하는 예제
penguins[penguins.isna().any(axis=1)]
species island bill_length_mm bill_depth_mm flipper_length_mm body_mass_g sex
| 3 | Adelie | Torgersen | NaN | NaN | NaN | NaN | NaN |
| 8 | Adelie | Torgersen | 34.1 | 18.1 | 193.0 | 3475.0 | NaN |
| 9 | Adelie | Torgersen | 42.0 | 20.2 | 190.0 | 4250.0 | NaN |
| 10 | Adelie | Torgersen | 37.8 | 17.1 | 186.0 | 3300.0 | NaN |
| 11 | Adelie | Torgersen | 37.8 | 17.3 | 180.0 | 3700.0 | NaN |
| 47 | Adelie | Dream | 37.5 | 18.9 | 179.0 | 2975.0 | NaN |
| 246 | Gentoo | Biscoe | 44.5 | 14.3 | 216.0 | 4100.0 | NaN |
| 286 | Gentoo | Biscoe | 46.2 | 14.4 | 214.0 | 4650.0 | NaN |
| 324 | Gentoo | Biscoe | 47.3 | 13.8 | 216.0 | 4725.0 | NaN |
| 336 | Gentoo | Biscoe | 44.5 | 15.7 | 217.0 | 4875.0 | NaN |
| 339 | Gentoo | Biscoe | NaN | NaN | NaN | NaN | NaN |
# NaN값이 1개인 애들은 넘어가고 여러개인 애들을 뽑는 방법
penguins[penguins.isna().sum(axis=1)>1]
species island bill_length_mm bill_depth_mm flipper_length_mm body_mass_g sex
| 3 | Adelie | Torgersen | NaN | NaN | NaN | NaN | NaN |
| 339 | Gentoo | Biscoe | NaN | NaN | NaN | NaN | NaN |
'''
펭귄의 경우 부리 사이즈로 성별 측정이 가능하다고 합니다.
괜히 모호한 성별을 부여하여 데이터에 혼돈을 주지 않기 위해 성별이 NaN인 값은 dataset에서 제거한다.
'''
# NaN값이 없는 모든 펭귄 출력 예제
penguins = penguins[penguins.notnull().all(axis=1)]
penguins
species island bill_length_mm bill_depth_mm flipper_length_mm body_mass_g sex
| 0 | Adelie | Torgersen | 39.1 | 18.7 | 181.0 | 3750.0 | Male |
| 1 | Adelie | Torgersen | 39.5 | 17.4 | 186.0 | 3800.0 | Female |
| 2 | Adelie | Torgersen | 40.3 | 18.0 | 195.0 | 3250.0 | Female |
| 4 | Adelie | Torgersen | 36.7 | 19.3 | 193.0 | 3450.0 | Female |
| 5 | Adelie | Torgersen | 39.3 | 20.6 | 190.0 | 3650.0 | Male |
| … | … | … | … | … | … | … | … |
| 338 | Gentoo | Biscoe | 47.2 | 13.7 | 214.0 | 4925.0 | Female |
| 340 | Gentoo | Biscoe | 46.8 | 14.3 | 215.0 | 4850.0 | Female |
| 341 | Gentoo | Biscoe | 50.4 | 15.7 | 222.0 | 5750.0 | Male |
| 342 | Gentoo | Biscoe | 45.2 | 14.8 | 212.0 | 5200.0 | Female |
| 343 | Gentoo | Biscoe | 49.9 | 16.1 | 213.0 | 5400.0 | Male |
333 rows × 7 columns
penguins
species island bill_length_mm bill_depth_mm flipper_length_mm body_mass_g sex
| 0 | Adelie | Torgersen | 39.1 | 18.7 | 181.0 | 3750.0 | Male |
| 1 | Adelie | Torgersen | 39.5 | 17.4 | 186.0 | 3800.0 | Female |
| 2 | Adelie | Torgersen | 40.3 | 18.0 | 195.0 | 3250.0 | Female |
| 3 | Adelie | Torgersen | NaN | NaN | NaN | NaN | NaN |
| 4 | Adelie | Torgersen | 36.7 | 19.3 | 193.0 | 3450.0 | Female |
| … | … | … | … | … | … | … | … |
| 339 | Gentoo | Biscoe | NaN | NaN | NaN | NaN | NaN |
| 340 | Gentoo | Biscoe | 46.8 | 14.3 | 215.0 | 4850.0 | Female |
| 341 | Gentoo | Biscoe | 50.4 | 15.7 | 222.0 | 5750.0 | Male |
| 342 | Gentoo | Biscoe | 45.2 | 14.8 | 212.0 | 5200.0 | Female |
| 343 | Gentoo | Biscoe | 49.9 | 16.1 | 213.0 | 5400.0 | Male |
344 rows × 7 columns
import seaborn as sns
penguins = sns.load_dataset('penguins')
penguins['Adelie'] = penguins['species'].apply(lambda x : 1 if x == 'Adelie' else 0)
penguins['Chinstrap'] = penguins['species'].apply(lambda x : 1 if x == 'Chinstrap' else 0)
penguins['Gentoo'] = penguins['species'].apply(lambda x : 1 if x == 'Gentoo' else 0)
penguins
species island bill_length_mm bill_depth_mm flipper_length_mm body_mass_g sex Adelie Chinstrap Gentoo
| 0 | Adelie | Torgersen | 39.1 | 18.7 | 181.0 | 3750.0 | Male | 1 | 0 | 0 |
| 1 | Adelie | Torgersen | 39.5 | 17.4 | 186.0 | 3800.0 | Female | 1 | 0 | 0 |
| 2 | Adelie | Torgersen | 40.3 | 18.0 | 195.0 | 3250.0 | Female | 1 | 0 | 0 |
| 3 | Adelie | Torgersen | NaN | NaN | NaN | NaN | NaN | 1 | 0 | 0 |
| 4 | Adelie | Torgersen | 36.7 | 19.3 | 193.0 | 3450.0 | Female | 1 | 0 | 0 |
| … | … | … | … | … | … | … | … | … | … | … |
| 339 | Gentoo | Biscoe | NaN | NaN | NaN | NaN | NaN | 0 | 0 | 1 |
| 340 | Gentoo | Biscoe | 46.8 | 14.3 | 215.0 | 4850.0 | Female | 0 | 0 | 1 |
| 341 | Gentoo | Biscoe | 50.4 | 15.7 | 222.0 | 5750.0 | Male | 0 | 0 | 1 |
| 342 | Gentoo | Biscoe | 45.2 | 14.8 | 212.0 | 5200.0 | Female | 0 | 0 | 1 |
| 343 | Gentoo | Biscoe | 49.9 | 16.1 | 213.0 | 5400.0 | Male | 0 | 0 | 1 |
344 rows × 10 columns
# 위 문제 선생님 코드
import seaborn as sns
penguins = sns.load_dataset('penguins')
species_values = penguins[species].unique()
for s in species_values:
penguins[s] = (penguins['species'] == s).astype('int')
penguins
'파이썬 > Pandas' 카테고리의 다른 글
| 5.Pandas 추가 메서드 - 2 (0) | 2023.05.02 |
|---|---|
| 4.Pandas 추가 메서드 - 1 (0) | 2023.05.02 |
| 3.Pandas - DataFrame - 2 (1) | 2023.05.02 |
| 2.Pandas - DataFrame - 1 (0) | 2023.05.02 |
| 1. Pandas Series (0) | 2023.05.02 |