
DataFrame fillna() 메서드
- fillna() 메서드는 NaN값을 원하는 값으로 바꿀 수 있다. 첫 인자로 변경하고자 하는 값을 전달하면 된다.
- value값으로 column label을 key로 갖는 딕셔너리를 전달하여 column마다 NaN을 대치하는 값을 각각 설정가능.
- limit 키워드 인자에 숫자를 전달하여 그 숫자만큼 column마다 변경 횟수를 제한할 수 있다.
- DataFrame을 value로 전달해서 NaN값을 대체할 수 있습니다. 다만 column label과 row index가 일치하지 않으면 적용되지 않는다.
# np.nan 으로 NaN값 만들 수 있음.
df = pd.DataFrame([[np.nan,2,np.nan,0],
[3,4,np.nan,1],
[np.nan,np.nan,np.nan,np.nan],
[np.nan,3,np.nan,4]], columns = list('ABCD'))
print(df)
print(df.fillna(0))

values = {'A':0,'B' :1,'C':2,'D':3} #column마다 원하는 값으로 NaN값을 채울 수 있다.
df.fillna(value=values)

df.fillna(value=values,limit=2) # column마다 2회씩만 변경가능.

df2 = pd.DataFrame(np.zeros((3,4)),columns = list('ABCㅎ')) # column도 ㅎ column이 D와 일치하지 않아서 NaN이 남아있음.
df.fillna(df2)
# row도 한줄 짧아서 마지막 row는 NaN이 그대로 남아있음
A B C D
| 0 | 0.0 | 2.0 | 0.0 | 0.0 |
| 1 | 3.0 | 4.0 | 0.0 | 1.0 |
| 2 | 0.0 | 0.0 | 0.0 | NaN |
| 3 | NaN | 3.0 | NaN | 4.0 |
#연습문제1
avg_age = int(titanic['age'].mean()) # 평균값 구함
titanic['age'] = titanic['age'].fillna(avg_age) # fillna에 inplace=True를 넣어주면 할당하지 않고도 알아서 바뀐값이 저장됨.
# print(titanic[titanic['age'].isna()])# age에 NaN값이 없음을 볼 수 있음\\
titanic.head(15)
titanic.count()

DataFrame astype() 메서드
- column의 자료형을 변경하는 메서드

d = {'col1' : [1,2], 'col2' : [3,4]}
df = pd.DataFrame(data=d)
df.dtypes

df.astype('int32').dtypes

df.astype({'col1': 'int32'}).dtypes # dictionary로 지정하여 하나씩 타입변경 가능
titanic['category2'] = titanic['sex'] + titanic['age'].astype('str')
titanic[['age','category2']]

DataFrame 실수 값을 카테고리 값으로 변환
- 실수 값을 크기 기준으로 하여 카테고리 값으로 변환하고 싶을 떄는 다음과 같은 명령을 사용합니다.
- cut : 실수 값의 경계선을 지정하는 경우 - 범위단위로 끊을때 유리
- x = 1차원 형태의 배열 형태가 옵니다.
- bins = int, 스칼라를 요소로 갖는 시퀀스가 옵니다.
- qcut : 개수가 똑같은 구간으로 나누는 경우(분위수) - 개수단위로 끊을 때 유리
- x = id ndarray 호은 Series
- q = int 혹은 분위수를 나타내는 1.이하의 실수를 요소로 갖는 list (ex. [0,. 25 ,. 5 ,. 75, 1.])
ages = [0,2,10,21,23,37,31,61,20,41,32,90,101]
bins = [1,20,30,50,70,100]
label = ['미성년자','청년','장년','중년','노년']
cats = pd.cut(ages,bins,labels = label)
cats #구간내에 없다면 NaN값이 들어간다.

print(type(cats)) # cut 명령이 반환하는 값은 categorical type이다.
# 속성으로 label 문자열을 codes 속성으로 정수로 인코딩한 카테고리 값을 가집니다.
print(cats.categories)
print(cats.codes) # 없으면 -1로 반환함.

df4 = pd.DataFrame(ages,columns = ['ages'])
df4['age_cat'] = pd.cut(df4.ages,bins,labels=label)
print(df4.dtypes)
# category 데이터는 문자열 취급이 안된다.(object type임)

df4['age_cat'].astype(str) + df4['ages'].astype(str)# 문자열로 쓰기 위해서는 astype해주는 과정이 필요함.
print(df4.dtypes)

df4
ages age_cat
| 0 | 0 | NaN |
| 1 | 2 | 미성년자 |
| 2 | 10 | 미성년자 |
| 3 | 21 | 청년 |
| 4 | 23 | 청년 |
| 5 | 37 | 장년 |
| 6 | 31 | 장년 |
| 7 | 61 | 중년 |
| 8 | 20 | 미성년자 |
| 9 | 41 | 장년 |
| 10 | 32 | 장년 |
| 11 | 90 | 노년 |
| 12 | 101 | NaN |
# qcut은 원하는 개수만큼 여기서는 4개 구간으로 나누어
data = np.random.randn(1000)
cats = pd.qcut(data, 4 , labels=['Q1','Q2','Q3','Q4'])
print(pd.value_counts(cats)) #같은 개수로 나누어 짐을 알 수 있다.
cats

bins = [0,20,30,50,70,100]
labels = ["미성년자", "청년", "장년", "중년", "노년"]
cuts = pd.cut(titanic['age'],bins,labels = label)
sorted_value_count = pd.value_counts(cuts).sort_index()
print(sorted_value_count)
sorted_value_count / sum(sorted_value_count)

DataFrame 인덱스 설정 및 제거
- set_index = 기존의 row 인덱스를 제거하고 데이터 column 중 하나를 인덱스로 설정합니다.
- reset_index =기존의 row 인덱스를 제거하고 인덱스를 데이터 열로 추가합니다.
import numpy as np
import pandas as pd
np.random.seed(0)
df1 = pd.DataFrame(np.vstack([list('ABCDE'), np.round(np.random.rand(3,5),2)]).T , columns = ['c1','c2','c3','c4'])
print(df1)

df2 = df1.set_index('c1')
print(df2)
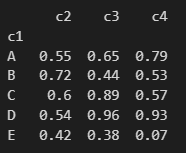
df2.set_index('c2') # 기존의 인덱스는 사라진다.
| c3 | c4 | |
| c2 | ||
| 0.55 | 0.65 | 0.79 |
| 0.72 | 0.44 | 0.53 |
| 0.6 | 0.89 | 0.57 |
| 0.54 | 0.96 | 0.93 |
| 0.42 | 0.38 | 0.07 |
- reset_index 메서드를 쓰면 보통의 자료열로 바꿀 수도 있다. 이떄 index column은 자료열의 가장 선두로 삽입됩니다.
- 인수중에 drop = True로 인수를 전달하면 인덱스 column을 보통의 자료열로 올리는 것이 아니라 그냥 버리게 된다.
- DataFrame의 인덱스는 정수로 된 디폴트 인덱스로 바뀝니다.
print(df2)
print(df2.reset_index())

print(df2)df2.reset_index(drop = True)

score = {
"이름":["일식", "이식", "삼식", "사식", "오식"],
"국어":[60, 70, 90, 80, 100],
"영어":[70, 86, 82, 88, 100],
"수학":[65, 82, 85, 90, 100]
}
scores = pd.DataFrame(score)
scores

inplace = True 를 사용하여 만듬과 동시에 할당도 가능하다.
scores.set_index('이름',inplace = True)scores
국어 영어 수학
| 이름 | |||
| 일식 | 60 | 70 | 65 |
| 이식 | 70 | 86 | 82 |
| 삼식 | 90 | 82 | 85 |
| 사식 | 80 | 88 | 90 |
| 오식 | 100 | 100 | 100 |
scores.reset_index(inplace = True)scores
이름 국어 영어 수학
| 0 | 일식 | 60 | 70 | 65 |
| 1 | 이식 | 70 | 86 | 82 |
| 2 | 삼식 | 90 | 82 | 85 |
| 3 | 사식 | 80 | 88 | 90 |
| 4 | 오식 | 100 | 100 | 100 |
DataFrame 다중 인덱스
- row나 column에 여러 계층을 가지는 인덱스 즉, 다중 인덱스를 설정할 수도 있습니다.
- DataFrame을 생성할 때 columns 인수에 당므 예제처럼 리스트의 리스트(행렬) 형태로 인덱스를 넣으면 다중 열 인덱스를 가지게 된다.
- 이름을 지정하면 더 편리하게 사용할 수 있습니다. column 인덱스들의 이름 지정은 columns 객체의 names 속성에 리스트를 넣어서 지정합니다.
- 다중 인덱스는 이름을 지정하면 더 편리한 사용이 가능하다. column 인덱스들의 이름 지정은 columns.names에 리스트를 넣어서 지정 가능하다.
np.random.seed(0)
df3 = pd.DataFrame(np.round(np.random.randn(5,4),2)
,columns = [['A','A','B','B'],
['C1','C2','C1','C2']])
df3

df3.columns.names = ['Cidx1','Cidx2']
df3

np.random.seed(0)
df4 = pd.DataFrame(np.round(np.random.randn(6,4),2),
columns = [['A','A','B','B'],
['C1','C2','C1','C2']],
index = [['M','M','M','F','F','F'],
['id_' + str(i+1) for i in range(3)] * 2])
df4.columns.names = ['Cidx1','Cidx2']
df4.index.names = ['Ridx1','Ridx2']
df4
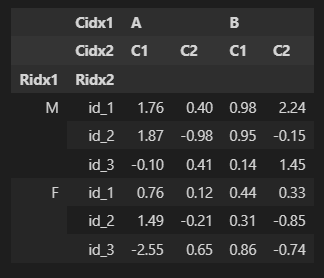
DataFrame row 인덱스와 column 인덱스 교환
- stack() 메서드
- column 인덱스를 row 인덱스로 변환해 줌
- unstack() 메서드
- row 인덱스를 column 인덱스로 변환해 줌
- level 속성을 사용하여 어느 위치에 추가해 줄지 결정 가능.
df4.stack('Cidx1') # level default값이 -1 이라서 가장 마지막에 추가된다.
df4.stack(0) # 은 위 값과 같은 결과를 가진다.

df4.unstack('Ridx2') # Ridx2가 column에 추가됨.
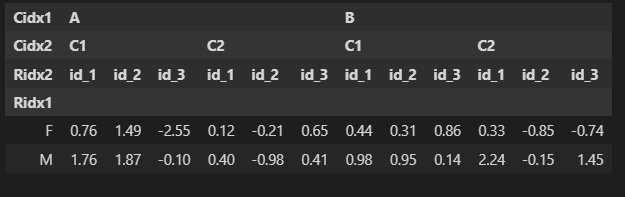
다중 인덱스가 있는 경우의 인덱싱
- 인덱스 값이 하나의 label이나 숫자가 아니라면 ()로 둘러싸인 튜플이 되어야 한다.
- loc 인덱서를 사용하는 경우에도 동일하게 튜플을 사용해서 인덱싱 해야 한다.
df3[('B','C1')]

print(df3.loc[0,('B','C1')])
df3.loc[0,('B','C1')] = 100
df3.loc[0,('B','C1')]

# 단, iloc 인덱서를 사용하는 경우에는 튜플 형태의 다중인덱스를 사용할 수 없다.
print(df3.iloc[0][2])
# 만약 하나의 레벨 값만 넣으면 다중 인덱스 중에서 가장 상위의 값을 지정한 것으로 반환합니다.
df3['A']

DataFrame 다중 인덱스가 있는 경우의 인덱싱
df4

print(df4.loc[:,('A','C1')])
df4.loc[('M','id_1'),('A','C1')]

print(df4.loc[('M','id_1'),:])df4.loc[('All','All'),:] = df4.sum()df4

DataFrame 다중 인덱스가 있는 경우의 인덱싱
- 다중 인덱스의 튜플 내에서는 콜론(:), 즉 슬라이스 기호를 사용할 수 없고, 대신 slice(None) 값을 사용해야 한다.
print(df4.loc[('M'),:])
df4.loc[('M',slice(None)),:]

다중 인덱스의 인덱스 순서 교환
- swaplevel(i, j, axis)
- i, j는 교환하고자 하는 인덱스 label이고,
- axis는 0일 때 row 인덱스, 1일 때 column인덱스를 뜻한다. default값은 0 임
df6 = df4.swaplevel('Cidx1','Cidx2',1)
df6
df5 = df4.swaplevel('Ridx1','Ridx2')
df5
DataFrame 다중 인덱스가 있는 경우의 정렬
- 다중 인덱스가 있는 DF를 sort_index로 정렬할 때는 level인수를 사용하여
- 어떤 인덱스를 기준으로 정렬하는지 알려줘야 한다.
print(df5.sort_index(level=0))
df6.sort_index(axis = 1,level = 0)

'파이썬 > Pandas' 카테고리의 다른 글
| 6. Pandas 추가 메서드 - 3 (0) | 2023.05.02 |
|---|---|
| 4.Pandas 추가 메서드 - 1 (0) | 2023.05.02 |
| 3.Pandas - DataFrame - 2 (1) | 2023.05.02 |
| 2.Pandas - DataFrame - 1 (0) | 2023.05.02 |
| 1. Pandas Series (0) | 2023.05.02 |