
DataFrame 고급 인덱싱
- Pandas에서 2차원 인덱싱을 지원을 하기 위한 추가적인 인덱서 속성
- loc = label 값 기반의 2차원 인덱싱 중 row에 대한 Series 추출에 사용
- row인덱싱 값은 정수 또는 row index 데이터이고,
- column 인덱싱 값은 label 문자열이다.
- loc인덱서의 인덱싱 값은 다음 중 하나이다.
- index 데이터
- index 데이터 슬라이스
- index 데이터 리스트
- 같은 row인덱스를 가지는 boolean Series
- 또는 위의 값들을 반환하는 함수
- loc 인덱서는 column에 대한 label 인덱싱이나 label 리스트 인 덱시은 불가능하다
- iloc = 순서를 나타내는 정수 기반의 2차원 인덱싱.
- column label 인덱싱이나 슬라이싱으로 사용할 경우 에러가 발생한다.
import numpy as np
v = np.arange(10,22).reshape(3,4)
DF = pd.DataFrame(v,index=list('abc'),columns=list('ABCD'))
print(DF)

print(DF.loc['a']) # row 데이터를 가져와도 Series형태이다.

print(DF.loc['b':'c'],end='\\n\\n' ) # = DF['b':'c'] ,여러개 가져올 때는 동일하게 DataFrame형태임.
print(DF.A>15) # 영문자 column에만 가능하다. series형태 를 비교연산하여 booltype Series 출력
print(DF['A'] > 15) # 둘은 같은 방식이나 아래 방식이 더 선호된다.

print(DF[DF.A>15]) # boolean Series로 row 기준 인덱싱한 예제.

loc과 iloc의 차이
- 슬라이싱 할 때 마지막 값을 loc은 포함하고, iloc은 포함하지 않는다.
- loc은 label을 바라보고 접근하는 방식이고,
- iloc은 int로 된 index를 바라보고 접근하는 방식이기 때문에 차이가 발생한다.
df2 = pd.DataFrame(np.arange(10,26).reshape(4,4),columns = list('ABCD'))
print(df2)

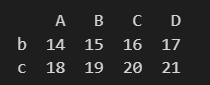
df2.loc[1:2] # 마지막값을 포함한다.
A B C D
| 1 | 14 | 15 | 16 | 17 |
| 2 | 18 | 19 | 20 | 21 |
df2.iloc[1:2] # 마지막값을 포함하지 않는다.
A B C D
| 1 | 14 | 15 | 16 | 17 |
loc 인덱서 표

인덱싱 값을 row와 column모두 받으려면
- DF.loc[ row인덱스, column인덱스 ]와 같은 형태로 사용한다.

print(DF['A']['a']) #접근순서의 차이가 발생할 뿐 둘은 같은 결과를 보여준다.
DF.loc['a','A']
print(DF.loc['a':'b','B':"D":2])
DF.loc[['a','b'],['B','D']]

DF.loc[DF.A>10,["C",'B']]
C B
| b | 16 | 15 |
| c | 20 | 19 |
iloc 인덱서
- 순서를 나타내는 정수 인덱스만 받는다.
- loc과 거의 동작방식은 동일하나 표현하는 방식과 범위만 다르다
- 인덱스가 하나만 들어가면 행을 선택한다.
print(DF.iloc[0,1])
print(DF.iloc[-1])
DF.iloc[-1] = DF.iloc[-1]*2
DF
A B C D
| a | 10 | 11 | 12 | 13 |
| b | 14 | 15 | 16 | 17 |
| c | 36 | 38 | 40 | 42 |
'파이썬 > Pandas' 카테고리의 다른 글
| 6. Pandas 추가 메서드 - 3 (0) | 2023.05.02 |
|---|---|
| 5.Pandas 추가 메서드 - 2 (0) | 2023.05.02 |
| 4.Pandas 추가 메서드 - 1 (0) | 2023.05.02 |
| 2.Pandas - DataFrame - 1 (0) | 2023.05.02 |
| 1. Pandas Series (0) | 2023.05.02 |