
Spark 설치
https://spark.apache.org/downloads.html
Downloads | Apache Spark
Download Apache Spark™ Choose a Spark release: Choose a package type: Download Spark: Verify this release using the and project release KEYS by following these procedures. Note that Spark 3 is pre-built with Scala 2.12 in general and Spark 3.2+ provides
spark.apache.org
- 위 링크로 이동하여 아래 1,2번과 같이 버전을 맞춰주고, 3. Download spark 링크를 클릭한다.
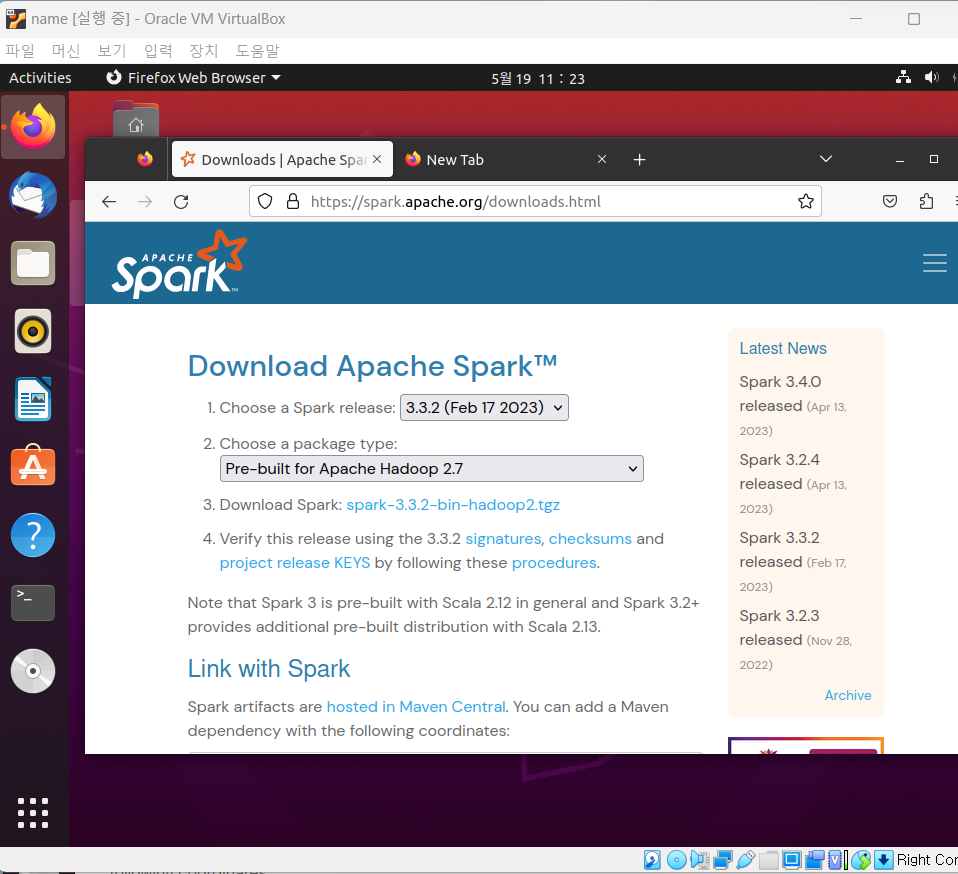
- 링크를 클릭하여 다운

- 압축해제 후 폴더 이름을 spark로 변경한 후 home/bigdata에 저장


환경변수 설정
- sudo gedit ~/.bashrc 명령어를 실행하여 아래 사진과 같이 환경변수 설정
- source ~/.bashrc로 설정 저장

- cd bigdata 로 폴더로 이동
- 나머지 분산환경에도 압축 해제한 spark 폴더를 scp 명령어로 전달
scp -r ~/bigdata/spark/ 192.168.56.102:/home/hadoop/bigdata/
scp -r ~/bigdata/spark/ 192.168.56.103:/home/hadoop/bigdata/
scp -r ~/bigdata/spark/ 192.168.56.104:/home/hadoop/bigdata/Workers로 동작할 노드 설정
- 아래 코드 실행 후 아래 그림과 같이 수정
cd ~/bigdata/spark/conf
cp workers.template workers
sudo gedit workers
Master 데몬 실행
- 메인 노드에서만 실행
cd ~/bigdata/spark/sbin && ./start-master.sh --host 192.168.56.101- jps 명령어로 아래와 같이 실행되고 있음을 확인하면 됩니다.

Workers 데몬 실행
- 나머지 분산 노드들에서 실행
cd ~/bigdata/spark/sbin && ./start-slave.sh spark://192.168.56.101:7077- jps 명령어로 아래와 같이 실행되고 있음을 확인

파이어폭스 브라우저 접속
- workers 3개가 정상 연결된 것을 확인할 수 있다.

PySpark 쉘 실행
cd ~/bigdata/spark/bin && ./pyspark --master spark://192.168.56.101:7077
'빅데이터 관리 > Hadoop' 카테고리의 다른 글
| SPARK 이론 (1) | 2023.05.19 |
|---|---|
| Hive - 2 (0) | 2023.05.16 |
| Hive - 1 (0) | 2023.05.16 |
| PIG 기본명령어 - 6 (0) | 2023.05.16 |
| PIG 기본 명령어 - 5 (1) | 2023.05.16 |