
Hive란?
Hive는 하둡에서 데이터를 처리하기 위한 데이터 웨어하우징 솔루션 중 하나입니다. Hive는 SQL을 사용하여 대규모 데이터 집합을 분석할 수 있도록 해주는 데이터 웨어하우스 솔루션입니다. Hive는 하둡 기반의 분산 데이터 저장소에서 SQL 쿼리를 실행할 수 있도록 해주는 인터페이스를 제공합니다.
Hive는 HiveQL이라는 SQL과 비슷한 언어를 사용하여 데이터에 대한 쿼리 및 분석을 수행합니다. HiveQL은 기존의 SQL과 유사하며, 사용자는 대부분의 경우 HiveQL을 배우기 쉽습니다. 또한 HiveQL은 사용자가 쉽게 커스텀 함수와 집계 함수를 정의하고 사용할 수 있도록 해줍니다. Hive는 맵리듀스와 같은 하둡의 다른 기술과 함께 사용될 수 있으며, 대규모 데이터 처리 및 분석 작업을 수행하는 데 매우 유용합니다.
Hive vs Pig
Hive와 PIG는 둘 다 Hadoop 기반의 데이터 처리 도구입니다. 기본적으로 두 처리 도구 전부 내부에서 맵리듀스 프레임워크를 사용하여 데이터 처리 작업을 수행하지만 둘의 목적과 기능이 다르며, 다른 방식으로 동작합니다. Hive는 SQL과 비슷한 HiveQL 쿼리 언어를 사용하여 대화형으로 데이터를 처리하는 데 중점을 둡니다.
반면 PIG는 데이터 처리 작업을 위해 스크립트 언어를 사용합니다. PIG 스크립트는 데이터 흐름을 정의하고, 중간 처리 결과를 다양한 방식으로 조작하고, 최종 결과를 생성하는 방식으로 동작합니다. 물론 두 도구는 함께 사용할 수 있습니다.
예를 들어 PIG로 처리한 중간 결과를 Hive로 불러와서 SQL 쿼리로 분석할 수 있습니다. 또는 Hive에서 처리된 결과를 PIG 스크립트로 조작할 수도 있습니다. Hive와 PIG는 각각의 장단점이 있으며, 사용하려는 데이터 처리 작업에 따라 선택할 수 있습니다. Hive는 SQL에 익숙한 사용자나 대화형으로 데이터를 처리하려는 경우에 유용합니다. PIG는 복잡한 데이터 처리 작업을 위해 구성 가능하며, 유연성과 확장성이 뛰어납니다.
Hive의 디스크 기반 데이터 처리 방식
Hive는 디스크 기반 데이터 처리 솔루션입니다. Hive는 하둡의 HDFS(Hadoop Distributed File System)와 같은 분산 파일 시스템에서 데이터를 읽고 쓰기 때문에, 디스크 I/O가 필요합니다.
그러나 Hive는 디스크 기반으로 동작하면서도, 적절한 인덱싱 및 분할 기술을 사용하여 쿼리의 성능을 최적화할 수 있습니다. 예를 들어, Hive는 데이터를 분할하여 여러 노드에서 병렬로 처리할 수 있으며, 필요한 경우에만 필요한 데이터를 로드하여 처리할 수 있도록 하는 것과 같은 기술을 사용합니다.
또한 Hive는 메모리 캐시를 사용하여 쿼리의 성능을 향상할 수 있습니다. 쿼리 실행 시 자주 사용되는 데이터는 메모리에 캐시 하여 디스크 I/O를 줄일 수 있습니다. 하지만 이러한 캐시 기능은 Hive가 메모리 기반으로 동작한다는 것을 의미하지 않습니다.
HIVE , PIG의 실행엔진 근황
Hive의 경우, 최근 버전에서는 Tez나 Spark와 같은 다른 실행 엔진을 사용할 수 있도록 지원합니다. Tez는 맵리듀스보다 효율적인 DAG(Directed Acyclic Graph) 기반의 실행 엔진입니다. Spark는 메모리 기반의 처리를 지원하며, 맵리듀스보다 더 빠른 속도로 데이터 처리 작업을 수행할 수 있습니다.
마찬가지로, PIG도 최근 버전에서는 Spark나 Tez와 같은 다른 실행 엔진을 사용할 수 있도록 지원합니다. 이러한 실행 엔진을 사용하면 맵리듀스보다 더 빠른 속도로 데이터 처리 작업을 수행할 수 있습니다. 따라서, Hive와 PIG는 맵리듀스를 사용하지 않을 수도 있으며, 다른 실행 엔진을 사용하여 데이터 처리 작업을 수행할 수 있습니다.
Hive 시작하기
- Hortonworks의 경우 Hive가 자동으로 깔려있기 때문에 다운로드 과정은 스킵하였습니다.
- 데이터가 저장되어 있는 파일을(저는 임의로 visits.txt로 만들었습니다.) /user/root/visit.txt 파일을 넣고
- pig 파일을 만들어서 특정 위치에 STORE 될 수 있도록 만들어 두고
- vi wh_visits.pig로 아래와 같은 파일을 생성해 줍니다.
--wh_house.pig : transforms visits.txt for a Hive table
visits = LOAD '/user/root/visits.txt' USING PigStorage(',');
potus = FILTER visits BY $19 MATCHES 'POTUS';
project_potus = FOREACH potus GENERATE
$0 AS lname:chararray,
$1 AS fname:chararray,
$6 AS time_of_arrival:chararray,
$11 AS appt_scheduled_time:chararray,
$21 AS location:chararray,
$25 AS comment:chararray;
STORE project_potus INTO '/warehouse/tablespace/managed/hive/wh_visits/';- wh_visits.pig의 LOAD부분을 보시면 /user/root/visits.txt로 되어있는 것을 볼 수 있는데, 이를 실행시키기 위해서 해당 위치로 visits.txt 파일과 wh_visits.pig 파일을 이동해주어야 합니다.
hadoop fs -put visits.txt /user/root
hadoop fs -put wh_visits.pig /user/root- pig wh_visits.pig로 HDFS에 올려둔 wh_visits.pig 파일을 실행시킵니다.
- hadoop fs -ls /warehouse/tablespace/managed/hive/wh_visits/ 로 명령어가 정상 작동하여 하둡 공간에 생성되었는지 확인합니다.

Hive에서 table 만들기
- hive 명령어로 실행 가능하며 아래 코드로 table을 생성한다.
create table wh_visits (
lname string,
fname string,
time_of_arrival string,
appt_scheduled_time string,
meeting_location string,
info_comment string
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS TEXTFILE;- show tables; 로 현재 테이블 확인
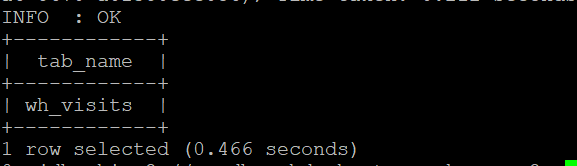
- select * from wh_visits limit 20; 로 visits.txt의 파일을 읽어서 만든 wh_visits 테이블 열어보기

- hive는 기존에 사용하던 SQL 문을 지원하기 때문에 SQL에 익숙한 사람이라면 편하게 사용이 가능하다.
스크립트 파일로 table 만들기
- 기존의 wh_visits 파일 삭제 - drop table wh_visits;
- vi wh_visits.hive로 파일 생성 후 아래 코드 입력
- 스크립트 실행 hive -f wh_visits.hive
create table wh_visits (
lname string,
fname string,
time_of_arrival string,
appt_scheduled_time string,
meeting_location string,
info_comment string
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS TEXTFILE;- 테이블 생성 확인
- hive 실행
- show tables

- 하지만 이렇게 생성한 wh_visits 테이블을 select문으로 찍어보면 데이터가 하나도 없는 것을 볼 수 있다.
- 그 이유로는 앞선 예제는 Pig 스크립트를 통해 데이터를 미리 HDFS에 배치하고, Hive에서 데이터가 위치한 경로에 테이블을 생성하면서 데이터가 자동으로 입력 됩니다.
- 하지만, 테이블을 삭제한 이후 Hive 스크립트를 통해 테이블을 생성하면, 테이블은 존재하지만, 데이터가 존재하지 않음.
- 현재까지 실습한 테이블의 구조는 내부 테이블이라 하며, 내부 테이블은 테이블을 삭제하면 테이블 메타 데이터와 데이터가 삭제된다.
- 하지만 외부 테이블을 삭제하면 테이블 메타 데이터는 삭제되지만 데이터는 삭제되지 않는다.
- 외부 테이블은 테이블 생성 시에 EXTERNAL 키워드를 넣어주면 된다.
- LOCATION 절을 추가로 사용하여 지정한 위치에 데이터가 존재한다는 것을 Hive에게 알려준다.
- 하이브에서 외부 테이블을 삭제하면, 하이브 내에서 스키마만 삭제될 뿐 데이터는 그대로 존재하기 때문에 중요한 데이터의 경우 실수를 방지하기 위해 외부 테이블로 만들 것을 권장한다.
'빅데이터 관리 > Hadoop' 카테고리의 다른 글
| SPARK 이론 (1) | 2023.05.19 |
|---|---|
| Hive - 2 (0) | 2023.05.16 |
| PIG 기본명령어 - 6 (0) | 2023.05.16 |
| PIG 기본 명령어 - 5 (1) | 2023.05.16 |
| PIG 기본명령어 - 4 (0) | 2023.05.16 |
Hive란?
Hive는 하둡에서 데이터를 처리하기 위한 데이터 웨어하우징 솔루션 중 하나입니다. Hive는 SQL을 사용하여 대규모 데이터 집합을 분석할 수 있도록 해주는 데이터 웨어하우스 솔루션입니다. Hive는 하둡 기반의 분산 데이터 저장소에서 SQL 쿼리를 실행할 수 있도록 해주는 인터페이스를 제공합니다.
Hive는 HiveQL이라는 SQL과 비슷한 언어를 사용하여 데이터에 대한 쿼리 및 분석을 수행합니다. HiveQL은 기존의 SQL과 유사하며, 사용자는 대부분의 경우 HiveQL을 배우기 쉽습니다. 또한 HiveQL은 사용자가 쉽게 커스텀 함수와 집계 함수를 정의하고 사용할 수 있도록 해줍니다. Hive는 맵리듀스와 같은 하둡의 다른 기술과 함께 사용될 수 있으며, 대규모 데이터 처리 및 분석 작업을 수행하는 데 매우 유용합니다.
Hive vs Pig
Hive와 PIG는 둘 다 Hadoop 기반의 데이터 처리 도구입니다. 기본적으로 두 처리 도구 전부 내부에서 맵리듀스 프레임워크를 사용하여 데이터 처리 작업을 수행하지만 둘의 목적과 기능이 다르며, 다른 방식으로 동작합니다. Hive는 SQL과 비슷한 HiveQL 쿼리 언어를 사용하여 대화형으로 데이터를 처리하는 데 중점을 둡니다.
반면 PIG는 데이터 처리 작업을 위해 스크립트 언어를 사용합니다. PIG 스크립트는 데이터 흐름을 정의하고, 중간 처리 결과를 다양한 방식으로 조작하고, 최종 결과를 생성하는 방식으로 동작합니다. 물론 두 도구는 함께 사용할 수 있습니다.
예를 들어 PIG로 처리한 중간 결과를 Hive로 불러와서 SQL 쿼리로 분석할 수 있습니다. 또는 Hive에서 처리된 결과를 PIG 스크립트로 조작할 수도 있습니다. Hive와 PIG는 각각의 장단점이 있으며, 사용하려는 데이터 처리 작업에 따라 선택할 수 있습니다. Hive는 SQL에 익숙한 사용자나 대화형으로 데이터를 처리하려는 경우에 유용합니다. PIG는 복잡한 데이터 처리 작업을 위해 구성 가능하며, 유연성과 확장성이 뛰어납니다.
Hive의 디스크 기반 데이터 처리 방식
Hive는 디스크 기반 데이터 처리 솔루션입니다. Hive는 하둡의 HDFS(Hadoop Distributed File System)와 같은 분산 파일 시스템에서 데이터를 읽고 쓰기 때문에, 디스크 I/O가 필요합니다.
그러나 Hive는 디스크 기반으로 동작하면서도, 적절한 인덱싱 및 분할 기술을 사용하여 쿼리의 성능을 최적화할 수 있습니다. 예를 들어, Hive는 데이터를 분할하여 여러 노드에서 병렬로 처리할 수 있으며, 필요한 경우에만 필요한 데이터를 로드하여 처리할 수 있도록 하는 것과 같은 기술을 사용합니다.
또한 Hive는 메모리 캐시를 사용하여 쿼리의 성능을 향상할 수 있습니다. 쿼리 실행 시 자주 사용되는 데이터는 메모리에 캐시 하여 디스크 I/O를 줄일 수 있습니다. 하지만 이러한 캐시 기능은 Hive가 메모리 기반으로 동작한다는 것을 의미하지 않습니다.
HIVE , PIG의 실행엔진 근황
Hive의 경우, 최근 버전에서는 Tez나 Spark와 같은 다른 실행 엔진을 사용할 수 있도록 지원합니다. Tez는 맵리듀스보다 효율적인 DAG(Directed Acyclic Graph) 기반의 실행 엔진입니다. Spark는 메모리 기반의 처리를 지원하며, 맵리듀스보다 더 빠른 속도로 데이터 처리 작업을 수행할 수 있습니다.
마찬가지로, PIG도 최근 버전에서는 Spark나 Tez와 같은 다른 실행 엔진을 사용할 수 있도록 지원합니다. 이러한 실행 엔진을 사용하면 맵리듀스보다 더 빠른 속도로 데이터 처리 작업을 수행할 수 있습니다. 따라서, Hive와 PIG는 맵리듀스를 사용하지 않을 수도 있으며, 다른 실행 엔진을 사용하여 데이터 처리 작업을 수행할 수 있습니다.
Hive 시작하기
- Hortonworks의 경우 Hive가 자동으로 깔려있기 때문에 다운로드 과정은 스킵하였습니다.
- 데이터가 저장되어 있는 파일을(저는 임의로 visits.txt로 만들었습니다.) /user/root/visit.txt 파일을 넣고
- pig 파일을 만들어서 특정 위치에 STORE 될 수 있도록 만들어 두고
- vi wh_visits.pig로 아래와 같은 파일을 생성해 줍니다.
--wh_house.pig : transforms visits.txt for a Hive table
visits = LOAD '/user/root/visits.txt' USING PigStorage(',');
potus = FILTER visits BY $19 MATCHES 'POTUS';
project_potus = FOREACH potus GENERATE
$0 AS lname:chararray,
$1 AS fname:chararray,
$6 AS time_of_arrival:chararray,
$11 AS appt_scheduled_time:chararray,
$21 AS location:chararray,
$25 AS comment:chararray;
STORE project_potus INTO '/warehouse/tablespace/managed/hive/wh_visits/';- wh_visits.pig의 LOAD부분을 보시면 /user/root/visits.txt로 되어있는 것을 볼 수 있는데, 이를 실행시키기 위해서 해당 위치로 visits.txt 파일과 wh_visits.pig 파일을 이동해주어야 합니다.
hadoop fs -put visits.txt /user/root
hadoop fs -put wh_visits.pig /user/root- pig wh_visits.pig로 HDFS에 올려둔 wh_visits.pig 파일을 실행시킵니다.
- hadoop fs -ls /warehouse/tablespace/managed/hive/wh_visits/ 로 명령어가 정상 작동하여 하둡 공간에 생성되었는지 확인합니다.
Hive에서 table 만들기
- hive 명령어로 실행 가능하며 아래 코드로 table을 생성한다.
create table wh_visits (
lname string,
fname string,
time_of_arrival string,
appt_scheduled_time string,
meeting_location string,
info_comment string
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS TEXTFILE;- show tables; 로 현재 테이블 확인
- select * from wh_visits limit 20; 로 visits.txt의 파일을 읽어서 만든 wh_visits 테이블 열어보기
- hive는 기존에 사용하던 SQL 문을 지원하기 때문에 SQL에 익숙한 사람이라면 편하게 사용이 가능하다.
스크립트 파일로 table 만들기
- 기존의 wh_visits 파일 삭제 - drop table wh_visits;
- vi wh_visits.hive로 파일 생성 후 아래 코드 입력
- 스크립트 실행 hive -f wh_visits.hive
create table wh_visits (
lname string,
fname string,
time_of_arrival string,
appt_scheduled_time string,
meeting_location string,
info_comment string
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS TEXTFILE;- 테이블 생성 확인
- hive 실행
- show tables
- 하지만 이렇게 생성한 wh_visits 테이블을 select문으로 찍어보면 데이터가 하나도 없는 것을 볼 수 있다.
- 그 이유로는 앞선 예제는 Pig 스크립트를 통해 데이터를 미리 HDFS에 배치하고, Hive에서 데이터가 위치한 경로에 테이블을 생성하면서 데이터가 자동으로 입력 됩니다.
- 하지만, 테이블을 삭제한 이후 Hive 스크립트를 통해 테이블을 생성하면, 테이블은 존재하지만, 데이터가 존재하지 않음.
- 현재까지 실습한 테이블의 구조는 내부 테이블이라 하며, 내부 테이블은 테이블을 삭제하면 테이블 메타 데이터와 데이터가 삭제된다.
- 하지만 외부 테이블을 삭제하면 테이블 메타 데이터는 삭제되지만 데이터는 삭제되지 않는다.
- 외부 테이블은 테이블 생성 시에 EXTERNAL 키워드를 넣어주면 된다.
- LOCATION 절을 추가로 사용하여 지정한 위치에 데이터가 존재한다는 것을 Hive에게 알려준다.
- 하이브에서 외부 테이블을 삭제하면, 하이브 내에서 스키마만 삭제될 뿐 데이터는 그대로 존재하기 때문에 중요한 데이터의 경우 실수를 방지하기 위해 외부 테이블로 만들 것을 권장한다.
'빅데이터 관리 > Hadoop' 카테고리의 다른 글
| SPARK 이론 (1) | 2023.05.19 |
|---|---|
| Hive - 2 (0) | 2023.05.16 |
| PIG 기본명령어 - 6 (0) | 2023.05.16 |
| PIG 기본 명령어 - 5 (1) | 2023.05.16 |
| PIG 기본명령어 - 4 (0) | 2023.05.16 |