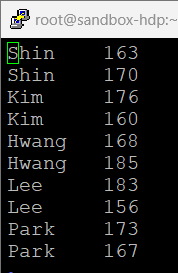
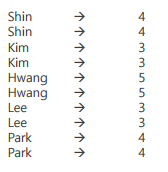
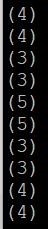
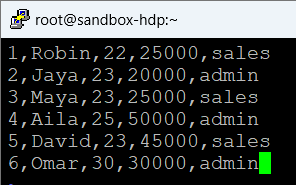
X 릴레이션에 FOREACH ~ GENERATE 구문을 통해 A 릴레이션의 이름 중 최댓값을 가진 tail 속성의 데이터를 저장
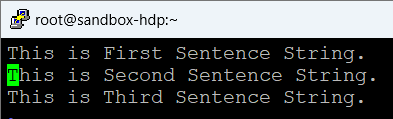
A = LOAD 'sample_data' AS (name:chararray, tall:int);
B = GROUP A All;
X = FOREACH B GENERATE A.name, MAX(A.tall);
DUMP X;
Min 도 Max 와 동일하게 동작한다.
Size
Size 함수는 데이터의 행의 지정한 속성의 데이터 길이를 반환
앞에서 실시한 A 릴레이션의 원본 데이터 중 첫 속성인 name의 값의 길이를 X 릴레이션에 저장 후 출력
X = FOREACH A GENERATE SIZE(name);
DUMP X;
Substract
일반적인 뺄셈과 같은 기능을 수행하지만, 숫자의 뺄셈이 아닌 각 데이터의 튜플을 비교하여 제거하는 기능을 수행
sample_data 수정
sample_data2 수정
2개의 릴레이션이 필요하기 때문에 A와 B 릴레이션을 생성하여 데이터 저장
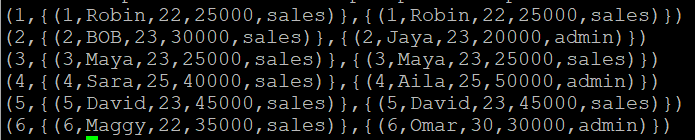
cogroup_data 릴레이션에 COGROUP 구문을 이용하여 A와 B 릴레이션의 sno 속성을 그룹화 후 출력
A, B 릴레이션의 sno 속성을 이용하여 이중 그룹화가 이루어진 것을 확인
A = LOAD 'sample_data' USING PigStorage(',') as (sno:int,name:chararray, age:int, salary:int, dept:chararray);
B = LOAD 'sample_data2' USING PigStorage(',') as (sno:int,name:chararray, age:int, salary:int, dept:chararray);
cogroup_data = COGROUP A by sno, B by sno;
DUMP cogroup_data;
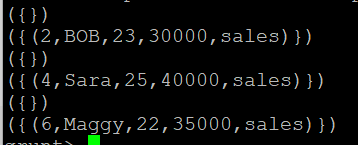
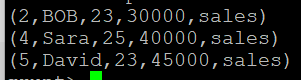
이 중 그룹화된 cogroup_data 릴레이션의 A 릴레이션과 B 릴레이션의 빼기 연산 수행
sum_group 릴레이션에 GROUP 구문을 이용하여 그룹화로 묶고, result 릴레이션에 FOREACH GENERATE 구문을 이용하여 각 그룹별로 묶인 튜플의 salary 속성값과, 전체 합계를 계산 후 출력
각 salary와 그 합계를 보여줌
sum_group = GROUP A all;
result = FOREACH sum_group GENERATE A.salary, SUM(A.salary);
DUMP result;
IN
데이터의 속성을 지정하여 해당 속성에 입력값을 가지고 있는지 유무를 검사하여 존재하는 튜플을 저장
A 릴레이션에서 sno 속성의 값이 2,4,5인 튜플을 X 릴레이션에 저장 후 출력
X = FILTER A BY sno IN (2, 4, 5);
DUMP X;
Tokenize
데이터의 띄어쓰기를 기준으로 하나의 튜플을 모아 백 자료형태로 만들어주는 기능을 수행
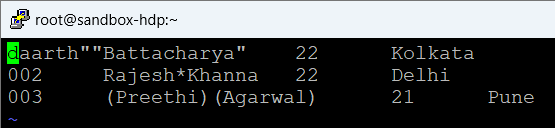
sample_data 수정
A 릴레이션에 f1 속성을 생성하여 데이터를 하나의 튜플로 저장
A 릴레이션 정의 시에 f1 속성 하나만 지정하였기 때문에 하나의 튜플로 저장됨.
A = LOAD 'sample_data' AS (f1:chararray);
DUMP A;
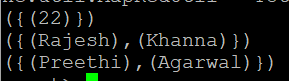
Tokenize를 수행하여 띄어쓰기를 기준으로 여러 개의 튜플을 묶은 백 자료형태로 X 릴레이션에 저장 후 출력
X = FOREACH A GENERATE TOKENIZE(f1);
DUMP X;
sample_data 수정 후 저장
A 릴레이션에 데이터의 속성과 형태를 지정하여 저장
token_A 릴레이션에 FOREACH ~ GENERATE 구문을 통해 name 속성을 tokenize 수행하여 저장 후 출력
A = LOAD 'sample_data' as (id:int, name:chararray, age:int, city:chararray);
token_A = FOREACH A GENERATE TOKENIZE(name);
DUMP token_A;
TextLoader()
해당 함수는 구조화되지 않은 데이터를 UTF-8 형식으로 읽어오는 기능을 수행함
앞서 사용한 A 릴레이션에 TextLoader()를 사용
텍스트 형식으로 데이터를 읽어오기 때문에 속성명과 데이터 타입 지정이 불가능하여 에러가 발생함.
A = LOAD 'sample_data' USING TextLoader() as (id:int,name:chararray, age:int, city:chararray);
DUMP A;
속성 이름과 데이터 타입을 지정하지 않고 TextLoader()만 사용하여 A 릴레이션에 저장 후 출력
입력한 데이터를 하나의 튜플의 텍스트 형태로 그대로 저장
스키마 구조 확인을 위해 DESCRIBE A; 실행
Text 형태로 불러왔기 때문에 스키마가 존재하지 않는다.
Top
백 자료형태의 상위 N 개의 튜플을 가져올 때 사용됨.
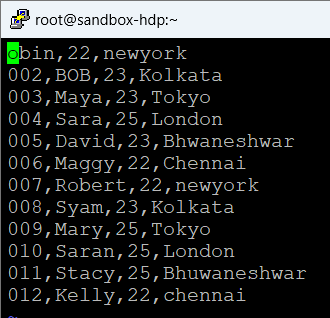
sample_data 수정 후 저장
A 릴레이션에 데이터 속성명과 데이터 타입을 지정하여 저장
A_group 릴레이션에 A 릴레이션의 age 속성을 기준으로 그룹화
A_top 릴레이션에 FOREACH GENERATE 구문을 통해 TOP(2,0, A) -> id를 기준으로 각 그룹의 상위 2개 데이터를 정정 후 출력
A = LOAD 'sample_data' USING PigStorage(',') as (id:int, name:chararray, age:int, city:chararray);
A_group = Group A BY age;
A_top = FOREACH A_group {
top = TOP(2, 0, A);
GENERATE top;
}
DUMP A_top;
ToMap
데이터의 특정 컬럼을 지정하여 키와 값의 형태로 변환할 수 있는 기능
A 릴레이션의 데이터 중 name 속성을 키로 설정하고, age 속성을 값으로 설정하여 X 릴레이션에 저장 후 출력