
PIG란
- 대용량 데이터를 다루기 위한 스크립트 언어이다.
- MapReduce는 분산처리를 가능하게 해주는 서비스이지만 한 번 처리를 위해서는 복잡한 java 로직이 필요하다. 이는 너무 어렵기 때문에 PIG와 HIVE라는 언어가 만들어졌다.
- PIG는 데이터 구조를 자세히 검토할 수 있는 여러 명령어를 제공하며, 입력데이터의 대표 부분 집합에 대해 표본실행이 가능하다는 장점이 있다.(오류 점검에 사용)
- 또한 확장가능성도 높다. 다만 소량의 데이터에는 MapReduce 과부하가 발생하기 떄문에 비효율적이다.
Hortonworks HDP 3.0을 다운로드하여 설치해 줍니다.
https://docs.cloudera.com/HDPDocuments/HDP3/HDP-3.0.0/release-notes/content/relnotes.html
HDP 3.0.0 Release Notes
HDP 3.0.0 Release Notes This document provides you with the latest information about the Hortonworks Data Platform (HDP) 3.0.0 release and its product documentation. Component VersionsThis section lists the official Apache versions of all the HDP 3.0.0 com
docs.cloudera.com
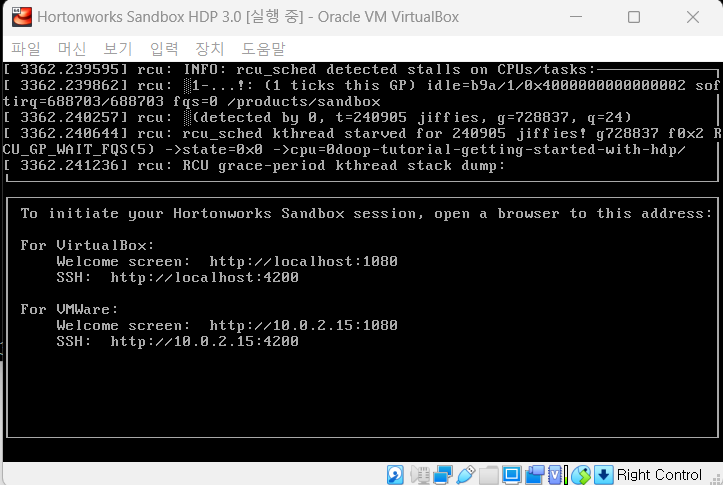
Hortonworks 실행 모습
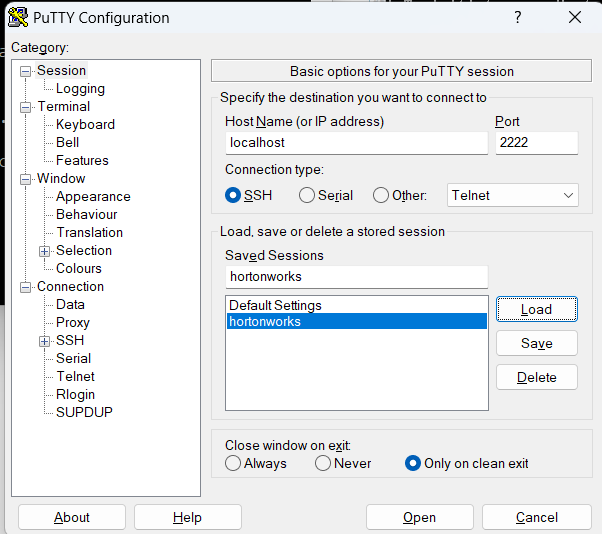
PUTTY를 설치해 아래와 같이 설정해 줍니다.
Download PuTTY - a free SSH and telnet client for Windows
Is Bitvise affiliated with PuTTY? Bitvise is not affiliated with PuTTY. We develop our SSH Server for Windows, which is compatible with PuTTY. Many PuTTY users are therefore our users as well. From time to time, they need to find the PuTTY download link. W
www.putty.org
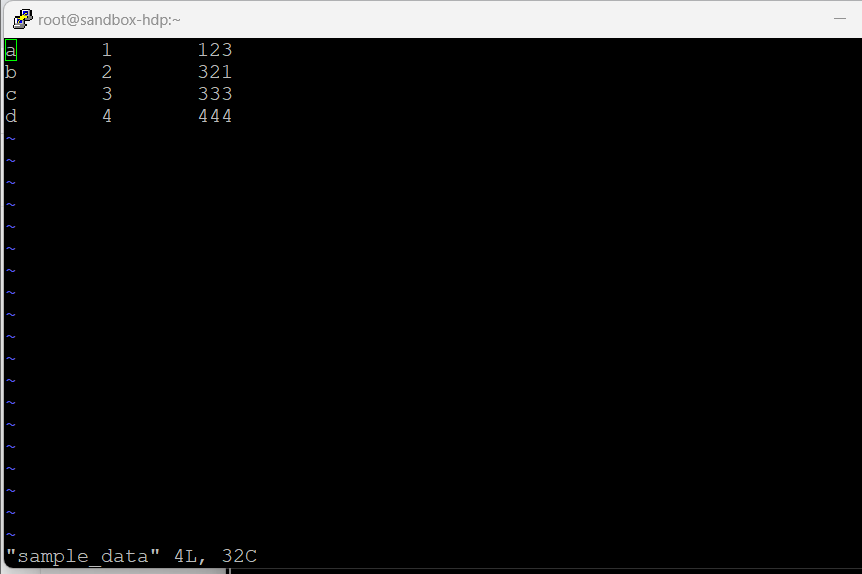
Hortonworks HDP 3.0은 GUI를 지원하지 않기에 vi 에디터 사용
gedit sample_data로 아래와 같은 파일 생성
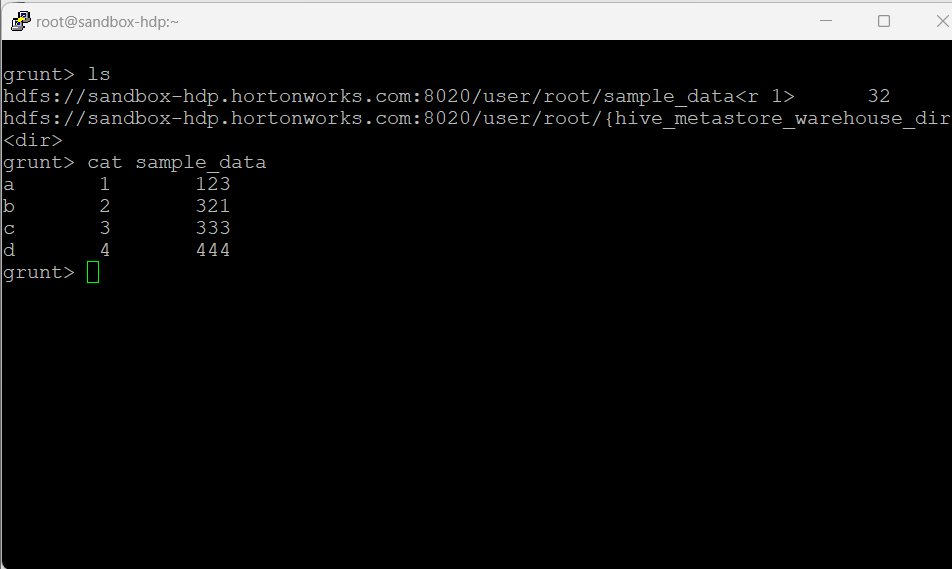
Pig를 통해 생성한 데이터 조작
- pig 명령어를 통해 접속
sample_data 수정
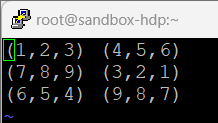
튜플 자료구조
- hadoop fs -put -f sample_data로 덮어쓰기 사용
- 튜플로 이루어져 있는 데이터의 튜플 이름을 정하고, 튜플 내의 각 속성의 이름과 데이터 타입을 결정
A = LOAD 'sample_data' AS (t1:tuple(t1a:int,t1b:int,t1c:int),t2:tuple(t2a:int,t2b:int,t2c:int));
DUMP A;
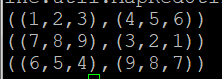
- 앞에서 실행한 A 릴레이션에 대해 t1 튜플의 t1a 속성과 t2 튜플의 첫 번째 속성을 X 릴레이션에 저장하고 출력

Bag 자료구조
- 입력한 데이터가 정상적으로 불러와지는지 확인 후 데이터를 조작
- sample_data 수정 후 hadoop에 저장
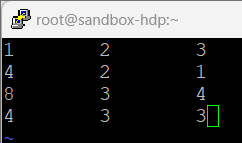
- 데이터의 속성 이름을 정하고, 데이터 타입을 결정한 후 출력
A = LOAD 'sample_data' as (f1:int, f2:int, f3:int);
DUMP A;
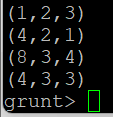
- Bag의 기본 형태는 Tuple과 다르지 않으며, 이와 같은 형태를 Outer Bag이라 함.
- A 릴레이션의 f1 속성을 기준으로 GROUP을 생성하여 X 릴레이션에 저장 후 출력
X = GROUP A BY f1;
DUMP X;
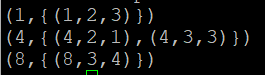
- X는 릴레이션 또는 튜플 모음으로 출력됨
- 릴레이션 X의 튜플에는 두 개의 필드가 있으며, 첫번째 필드는 f1의 속성값(1,4,8)을 기준으로 그룹을 지어 중복되는 속성값을 지닌 튜플은 하나의 형태로 묶어서 표현
- 이와 같은 형태를 Inner Bag이라 함.
Map 자료구조
- sample_data 수정 및 hadoop 저장
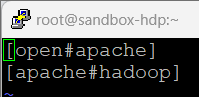
A = LOAD 'sample_data' AS (M:map []);
DESCRIBE A;
DUMP A;
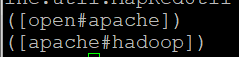
- open#apache의 # 기호는 키와 값을 구분 짓는 기호를 뜻함
산술 연산자 (나머지 %)
- sample_data 수정 후 hadoop에 저장
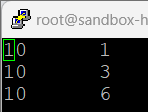
- 데이터의 속성 이름과 데이터 형태를 정하고, 출력
A = LOAD 'sample_data' AS (f1:int, f2:int);
DUMP A;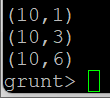
- 산술 연산자 적용
- A 릴레이션의 f1, f2 속성과 f1과 f2를 나누기 연산하고, 나머지를 세 번째 속성으로 지정하여 X 릴레이션에 저장 후 출력
X = FOREACH A GENERATE f1, f2, f1%f2;
DUMP X;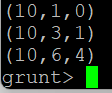
산술 연산자 + , - * , / 모두 사용 가능하다.
Bollean 연산자
- AND, OR, IN, NOT을 사용할 수 있음
- 좌측 그림과 같이 데이터를 수정
- 수정 후 HDFS에 저장
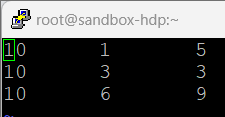
- A 릴레이션에 데이터의 속성명과 데이터 형태를 정하고, X릴레이션에 FILTER BY 구문을 이용하여 조건에 부합하는 데이터만 저장 후 출력
A = LOAD 'sample_data' as (f1:int, f2:int, f3:int);
X = FILTER A BY (f1==8) OR (NOT (f2+f3 > f1));
DUMP A;
DUMP X;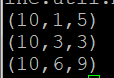
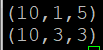
- DUMP X; 의 경우 (f1==8) 조건을 통해 f1의 데이터는 8이 없기 때문에 False이지만 뒤의 (NOT (f2+f3> f1))의 조건에서 (10,1,5), (10,3,3) 데이터가 만족하여 두 개의 데이터만 X 릴레이션에 저장됨.
산술 연산자 ==,!=, < , > , <= , >=
- X 릴레이션에 앞장에서 사용한 A 릴레이션의 f2 속성 값이 2보다 크고, f3 속성 값이 9인 데이터를 저장 후 출력
X = FILTER A BY (f2 > 2) and f3 == 9;
DUMP X;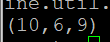
'빅데이터 관리 > Hadoop' 카테고리의 다른 글
| PIG 기본명령어 - 4 (0) | 2023.05.16 |
|---|---|
| PIG 기본 명령어 - 3 (0) | 2023.05.15 |
| PIG 기본 명령어 - 2 (0) | 2023.05.15 |
| FLUME - Tomcat 연결해보기 (0) | 2023.05.11 |
| 하둡 기본 명령어 - 1 (0) | 2023.05.09 |
PIG란
- 대용량 데이터를 다루기 위한 스크립트 언어이다.
- MapReduce는 분산처리를 가능하게 해주는 서비스이지만 한 번 처리를 위해서는 복잡한 java 로직이 필요하다. 이는 너무 어렵기 때문에 PIG와 HIVE라는 언어가 만들어졌다.
- PIG는 데이터 구조를 자세히 검토할 수 있는 여러 명령어를 제공하며, 입력데이터의 대표 부분 집합에 대해 표본실행이 가능하다는 장점이 있다.(오류 점검에 사용)
- 또한 확장가능성도 높다. 다만 소량의 데이터에는 MapReduce 과부하가 발생하기 떄문에 비효율적이다.
Hortonworks HDP 3.0을 다운로드하여 설치해 줍니다.
https://docs.cloudera.com/HDPDocuments/HDP3/HDP-3.0.0/release-notes/content/relnotes.html
HDP 3.0.0 Release Notes
HDP 3.0.0 Release Notes This document provides you with the latest information about the Hortonworks Data Platform (HDP) 3.0.0 release and its product documentation. Component VersionsThis section lists the official Apache versions of all the HDP 3.0.0 com
docs.cloudera.com
Hortonworks 실행 모습
PUTTY를 설치해 아래와 같이 설정해 줍니다.
Download PuTTY - a free SSH and telnet client for Windows
Is Bitvise affiliated with PuTTY? Bitvise is not affiliated with PuTTY. We develop our SSH Server for Windows, which is compatible with PuTTY. Many PuTTY users are therefore our users as well. From time to time, they need to find the PuTTY download link. W
www.putty.org
Hortonworks HDP 3.0은 GUI를 지원하지 않기에 vi 에디터 사용
gedit sample_data로 아래와 같은 파일 생성
Pig를 통해 생성한 데이터 조작
- pig 명령어를 통해 접속
sample_data 수정
튜플 자료구조
- hadoop fs -put -f sample_data로 덮어쓰기 사용
- 튜플로 이루어져 있는 데이터의 튜플 이름을 정하고, 튜플 내의 각 속성의 이름과 데이터 타입을 결정
A = LOAD 'sample_data' AS (t1:tuple(t1a:int,t1b:int,t1c:int),t2:tuple(t2a:int,t2b:int,t2c:int));
DUMP A;
- 앞에서 실행한 A 릴레이션에 대해 t1 튜플의 t1a 속성과 t2 튜플의 첫 번째 속성을 X 릴레이션에 저장하고 출력
Bag 자료구조
- 입력한 데이터가 정상적으로 불러와지는지 확인 후 데이터를 조작
- sample_data 수정 후 hadoop에 저장
- 데이터의 속성 이름을 정하고, 데이터 타입을 결정한 후 출력
A = LOAD 'sample_data' as (f1:int, f2:int, f3:int);
DUMP A;
- Bag의 기본 형태는 Tuple과 다르지 않으며, 이와 같은 형태를 Outer Bag이라 함.
- A 릴레이션의 f1 속성을 기준으로 GROUP을 생성하여 X 릴레이션에 저장 후 출력
X = GROUP A BY f1;
DUMP X;
- X는 릴레이션 또는 튜플 모음으로 출력됨
- 릴레이션 X의 튜플에는 두 개의 필드가 있으며, 첫번째 필드는 f1의 속성값(1,4,8)을 기준으로 그룹을 지어 중복되는 속성값을 지닌 튜플은 하나의 형태로 묶어서 표현
- 이와 같은 형태를 Inner Bag이라 함.
Map 자료구조
- sample_data 수정 및 hadoop 저장
A = LOAD 'sample_data' AS (M:map []);
DESCRIBE A;
DUMP A;- open#apache의 # 기호는 키와 값을 구분 짓는 기호를 뜻함
산술 연산자 (나머지 %)
- sample_data 수정 후 hadoop에 저장
- 데이터의 속성 이름과 데이터 형태를 정하고, 출력
A = LOAD 'sample_data' AS (f1:int, f2:int);
DUMP A;- 산술 연산자 적용
- A 릴레이션의 f1, f2 속성과 f1과 f2를 나누기 연산하고, 나머지를 세 번째 속성으로 지정하여 X 릴레이션에 저장 후 출력
X = FOREACH A GENERATE f1, f2, f1%f2;
DUMP X;산술 연산자 + , - * , / 모두 사용 가능하다.
Bollean 연산자
- AND, OR, IN, NOT을 사용할 수 있음
- 좌측 그림과 같이 데이터를 수정
- 수정 후 HDFS에 저장
- A 릴레이션에 데이터의 속성명과 데이터 형태를 정하고, X릴레이션에 FILTER BY 구문을 이용하여 조건에 부합하는 데이터만 저장 후 출력
A = LOAD 'sample_data' as (f1:int, f2:int, f3:int);
X = FILTER A BY (f1==8) OR (NOT (f2+f3 > f1));
DUMP A;
DUMP X;
- DUMP X; 의 경우 (f1==8) 조건을 통해 f1의 데이터는 8이 없기 때문에 False이지만 뒤의 (NOT (f2+f3> f1))의 조건에서 (10,1,5), (10,3,3) 데이터가 만족하여 두 개의 데이터만 X 릴레이션에 저장됨.
산술 연산자 ==,!=, < , > , <= , >=
- X 릴레이션에 앞장에서 사용한 A 릴레이션의 f2 속성 값이 2보다 크고, f3 속성 값이 9인 데이터를 저장 후 출력
X = FILTER A BY (f2 > 2) and f3 == 9;
DUMP X;
'빅데이터 관리 > Hadoop' 카테고리의 다른 글
| PIG 기본명령어 - 4 (0) | 2023.05.16 |
|---|---|
| PIG 기본 명령어 - 3 (0) | 2023.05.15 |
| PIG 기본 명령어 - 2 (0) | 2023.05.15 |
| FLUME - Tomcat 연결해보기 (0) | 2023.05.11 |
| 하둡 기본 명령어 - 1 (0) | 2023.05.09 |