
하둡 설치에 대해서 궁금하시다면 메일 바랍니다. 따로 자료 공유 드리겠습니다.
- 데이터를 수집하여 하둡에 분산 저장한다.
- 몽고 DB도 하둡같은 기술을 사용하여 분산저장으로 구현한다.
- FLUME은 txt 같은 로그파일을 수집할 때 많이 사용한다.
- Sqoop은 정형데이터를 수집할 때 많이 사용한다.
리눅스 설정
- 가상머신 4개를 만들어 하둡 분산환경 시스템을 구축하자.
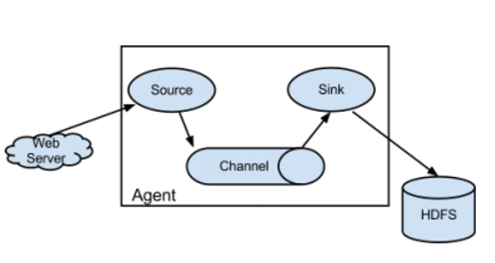
HDFS :Hadoop Distributed file system
Web Server : Tomcat, Nginx : txt 파일로 로그를 관리함 → Agent의 설정으로 5분에 한 번씩 하둡에 저장하는 등의 방식으로 설정 가능. - Web Server 대신에 Linux System(다중사용자용 로그발생관리), FTP 등이 들어가기서 해당 장소에서의 로그 수집을 한다.
Source : 데이터를 읽어들임
Channel : 데이터 이동통로
Sink : 데이터 저장할 곳
Agent : 데이터를 수집하는 요원처럼 동작한다는 의미
- Agent는 복수개가 가능하다.
Flume 사용 방법
- Web Server에 해당하는 부분만 변경이 가능하며 설정 옵션에 대한 숙지만 한다면 사용법이 대부분 비슷하다고 느꼈다. 그래서 Tomcat을 사용한 웹 로그 수집 방법만 올립니다.
Flume 설치
- wget http://archive.apache.org/dist/flume/1.9.0/apache-flume-1.9.0-bin.tar.gz
- tar -xvf 파일명으로 압축 해제
- 보기 편하게 이름 변경
- mv apache-flume-1.9.0-bin flume
Apache Tomcat 설치
- 설치하여 이름을 변경한 flume 폴더 밑의 bin 폴더로 이동
- cd /flume/bin
- wget https://mirror.navercorp.com/apache/tomcat/tomcat-8/v8.5.88/bin/apache-tomcat-8.5.88.tar.gz
- tar -xvf 파일명으로 압축 해제
- mv apache-tomcat-8.5.88 tomcat으로 파일명 변경
환경 변수 설정
sudo gedit ~/.bashrc 수정
# ~/.bashrc: executed by bash(1) for non-login shells.
# see /usr/share/doc/bash/examples/startup-files (in the package bash-doc)
# for examples
# If not running interactively, don't do anything
case $- in
*i*) ;;
*) return;;
esac
# don't put duplicate lines or lines starting with space in the history.
# See bash(1) for more options
HISTCONTROL=ignoreboth
# append to the history file, don't overwrite it
shopt -s histappend
# for setting history length see HISTSIZE and HISTFILESIZE in bash(1)
HISTSIZE=1000
HISTFILESIZE=2000
# check the window size after each command and, if necessary,
# update the values of LINES and COLUMNS.
shopt -s checkwinsize
# If set, the pattern "**" used in a pathname expansion context will
# match all files and zero or more directories and subdirectories.
#shopt -s globstar
# make less more friendly for non-text input files, see lesspipe(1)
[ -x /usr/bin/lesspipe ] && eval "$(SHELL=/bin/sh lesspipe)"
# set variable identifying the chroot you work in (used in the prompt below)
if [ -z "${debian_chroot:-}" ] && [ -r /etc/debian_chroot ]; then
debian_chroot=$(cat /etc/debian_chroot)
fi
# set a fancy prompt (non-color, unless we know we "want" color)
case "$TERM" in
xterm-color|*-256color) color_prompt=yes;;
esac
# uncomment for a colored prompt, if the terminal has the capability; turned
# off by default to not distract the user: the focus in a terminal window
# should be on the output of commands, not on the prompt
#force_color_prompt=yes
if [ -n "$force_color_prompt" ]; then
if [ -x /usr/bin/tput ] && tput setaf 1 >&/dev/null; then
# We have color support; assume it's compliant with Ecma-48
# (ISO/IEC-6429). (Lack of such support is extremely rare, and such
# a case would tend to support setf rather than setaf.)
color_prompt=yes
else
color_prompt=
fi
fi
if [ "$color_prompt" = yes ]; then
PS1='${debian_chroot:+($debian_chroot)}\[\033[01;32m\]\u@\h\[\033[00m\]:\[\033[01;34m\]\w\[\033[00m\]\$ '
else
PS1='${debian_chroot:+($debian_chroot)}\u@\h:\w\$ '
fi
unset color_prompt force_color_prompt
# If this is an xterm set the title to user@host:dir
case "$TERM" in
xterm*|rxvt*)
PS1="\[\e]0;${debian_chroot:+($debian_chroot)}\u@\h: \w\a\]$PS1"
;;
*)
;;
esac
# enable color support of ls and also add handy aliases
if [ -x /usr/bin/dircolors ]; then
test -r ~/.dircolors && eval "$(dircolors -b ~/.dircolors)" || eval "$(dircolors -b)"
alias ls='ls --color=auto'
#alias dir='dir --color=auto'
#alias vdir='vdir --color=auto'
alias grep='grep --color=auto'
alias fgrep='fgrep --color=auto'
alias egrep='egrep --color=auto'
fi
# colored GCC warnings and errors
#export GCC_COLORS='error=01;31:warning=01;35:note=01;36:caret=01;32:locus=01:quote=01'
# some more ls aliases
alias ll='ls -alF'
alias la='ls -A'
alias l='ls -CF'
# Add an "alert" alias for long running commands. Use like so:
# sleep 10; alert
alias alert='notify-send --urgency=low -i "$([ $? = 0 ] && echo terminal || echo error)" "$(history|tail -n1|sed -e '\''s/^\s*[0-9]\+\s*//;s/[;&|]\s*alert$//'\'')"'
# Alias definitions.
# You may want to put all your additions into a separate file like
# ~/.bash_aliases, instead of adding them here directly.
# See /usr/share/doc/bash-doc/examples in the bash-doc package.
if [ -f ~/.bash_aliases ]; then
. ~/.bash_aliases
fi
# enable programmable completion features (you don't need to enable
# this, if it's already enabled in /etc/bash.bashrc and /etc/profile
# sources /etc/bash.bashrc).
if ! shopt -oq posix; then
if [ -f /usr/share/bash-completion/bash_completion ]; then
. /usr/share/bash-completion/bash_completion
elif [ -f /etc/bash_completion ]; then
. /etc/bash_completion
fi
fi
export CATALINA_HOME=/home/hadoop/tomcat
export HADOOP_OPTS="$HADOOP_OPTS -Djava.library.path=$HADOOP_HOME/lib/native"
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export HADOOP_HOME=/home/hadoop/bigdata/hadoop
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
export PATH=$PATH:$JAVA_HOME/bin
export PATH- source ~/. bashrc로 저장
Tomcat 실행
- cd tomcat/bin
- ./startup.sh
- firefox 실행 후 localhost:8888
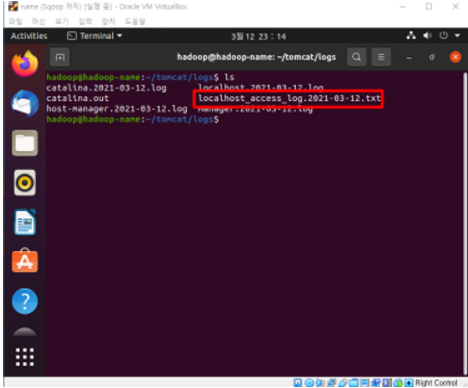
- cd ~/tomcat/logs
- ls
- 아래 그림처럼 빨간 박스로 된 로그파일이 존재해야 함.
Tomcat - Flume - Hadoop 환경설정
- cd ~/bigdata/flume/conf
- touch flume-hdfs-tomcat
- gedit flume-hdfs-tomcat
- 아래와 같이 수정
# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
# KIND, either express or implied. See the License for the
# specific language governing permissions and limitations
# under the License.
# The configuration file needs to define the sources,
# the channels and the sinks.
# Sources, channels and sinks are defined per agent,
# in this case called 'agent'
agent.sources = s1
agent.channels = c1
agent.sinks = k1
# For each one of the sources, the type is defined
agent.sources.s1.type = exec
agent.sources.s1.command = tail -f /home/hadoop/tomcat/logs/localhost_access_log.2023-05-11.txt
agent.sources.s1.interceptor = i1
agent.sources.s1.interceptors.il.type = timestamp
# The channel can be defined as follows.
agent.sources.s1.channels = c1
# Each sink's type must be defined
agent.sinks.k1.type = logger
#Specify the channel the sink should use
agent.sinks.k1.type = hdfs
agent.sinks.k1.channel = c1
agent.sinks.k1.hdfs.path = hdfs://hadoop-name:9000/flume/tomcatevents/%y-%m-%d/%H%M/
agent.sinks.k1.hdfs.writeFormat = Text
agent.sinks.k1.hdfs.useLocalTimeStamp = true
# Each channel's type is defined.
agent.channels.c1.type = memory
# Other config values specific to each type of channel(sink or source)
# can be defined as well
# In this case, it specifies the capacity of the memory channel
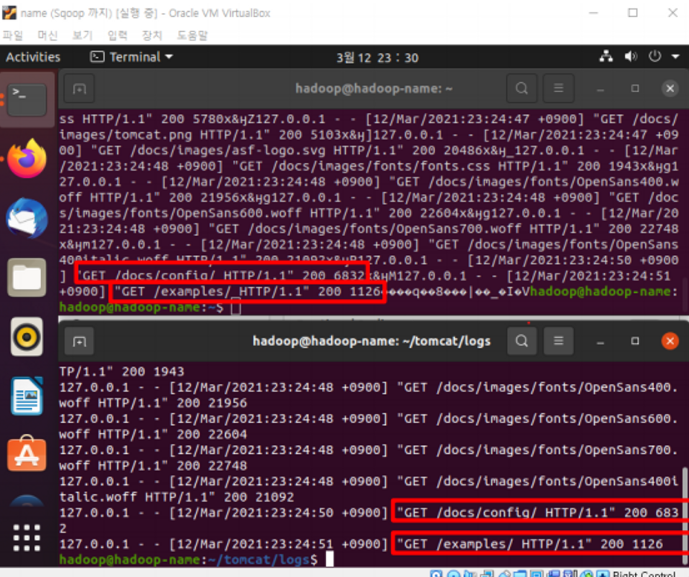
agent.channels.c1.capacity = 100- ./flume-ng agent --conf-file ../conf/flume-hdfs-tomcat --name agent -Dflume.root.logger=INFO,console 로 실행
- web에서 발생하는 요청에 따라 로그가 생성된다.
HDFS 로그 저장 확인
- hadoop fs -ls /flume
- 경로에 tomcatevents 디렉터리가 생성되어 있음을 볼 수 있다.
- 이 디렉토리 안에 로그 파일들이 저장된다.
- haddop fs -ls /flume/tomcatevents/* 로 모든 로그 파일을 열어볼 수 있다.
'빅데이터 관리 > Hadoop' 카테고리의 다른 글
| PIG 기본명령어 - 4 (0) | 2023.05.16 |
|---|---|
| PIG 기본 명령어 - 3 (0) | 2023.05.15 |
| PIG 기본 명령어 - 2 (0) | 2023.05.15 |
| PIG 기본 명령어 - 1 (0) | 2023.05.15 |
| 하둡 기본 명령어 - 1 (0) | 2023.05.09 |