
서울시 혼잡도 기반 장소 추천 프로젝트
- 2023.05.22 ~ 2023.06.30 동안 진행했던 프로젝트입니다. 약 10일 정도는 spring 공부를 위해 시간을 사용했으며, Backend 개발에 사용한 시간은 4주입니다. Playdata Encore에서 진행한 마지막 프로젝트이며, 제가 담당한 역할은 Backend입니다.
- github : https://github.com/byeong-chang/Stand_Up_Seoul
GitHub - byeong-chang/Stand_Up_Seoul: Playdata final project - 서울시 지하철 데이터를 사용하여 혼잡도를 분석
Playdata final project - 서울시 지하철 데이터를 사용하여 혼잡도를 분석하여 서비스 제공 - GitHub - byeong-chang/Stand_Up_Seoul: Playdata final project - 서울시 지하철 데이터를 사용하여 혼잡도를 분석하여 서
github.com
1. 프로젝트 소개
1) 팀원별 역할
우상욱(팀장) : 데이터엔지니어링
(1) 데이터베이스 설계 및 구축
(2) 맛집, 명소 데이터 크롤링
(3) Airflow 활용 운영 데이터 파이프라인 설계 및 구축
(4) Aws Lambda 활용, 딥러닝 모델(Tensorflow)을 활용한 별점 업데이트 파이프라인 설계 및 구축
(5) 데이터웨어하우스 설계 및 구축(Aws Redshift)
(6) Superset 데이터 시각화 서버 구축 및 DB, DW 연동
(7) 머신러닝 API 서버 구현(FastAPI)
(8) Airflow 활용 ML 모델 자동화 배포 파이프라인 설계 및 구현
(9) 로그 데이터 수집 및 가공 파이프라인 설계
(10) 발표
김호영 : 데이터분석, 머신러닝
(1) 데이터 가공/전처리/시각화
(2) 지하철 승하차 인원, 장소 혼잡도 모델 설계 및 구축
(3) Aws Lambda 활용, 딥러닝(Tensorflow) 모델을 활용한 별점 업데이트 파이프라인 설계 및 구축
(4) 대시보드 구축 및 데이터 분석(Superset)
(5) 머신러닝 API 서버 구현(FastAPI)
(6) 웹 사이트 로그 데이터 가공 및 분석
민병창 : 백엔드
(1) 데이터베이스 설계 및 연동
(2) Mysql Trigger, Event Trigger 작성
(3) Spring Boot와 JWT를 활용한 회원가입/로그인 구현
(4) Spring Boot Interceptor request 로그 데이터 수집 api 구현
(5) Fast api loggers를 활용한 로그 데이터 수집 api 구현
(6) Fast api model 예측값 전달 API 개발
(7) 실시간 지도 기반 추천 알고리즘 개발
(8) AWS EC2를 활용한 spring, react 연동 및 배포
(9) AWS IAM을 사용한 spring, s3 통신 구현
(10) Git repository개설 및 Git branch 전략 설정
(11) 문서정리 ,자료정리, 서기 및 발표
김민수 : 백엔드
(1) Spring Boot와 React 개발환경 설정
(2) Spring Boot를 활용한 실시간 혼잡도 api 구현
(3) Spring Boot를 활용한 실시간 혼잡도 장소 api 구현
(4) Spring Boot를 활용한 사용자 마이페이지 api 구현
(5) AWS EC2를 활용한 spring, react 연동 및 배포
(6) Git repository개설 및 Git branch 전략 설정
김경목 : 프론트엔드
(1) 웹 디자인 설계 및 구현
(2) 사용자 인터페이스 개발
(3) 웹 애플리케이션 개발 환경 설정
(4) Responsiveness(반응형) 개발
(5) UI/UX 개선
(6) 프론트엔드 프레임워크와 라이브러리 활용
(7) 테스팅과 디버깅
2) 사용 기술
- 아래 기술표는 저희 프로젝트에 사용된 기술입니다.
2. 시스템 구성도
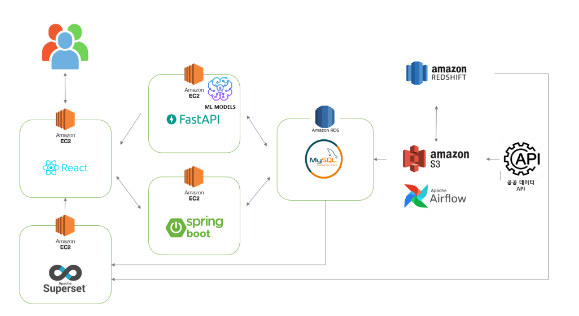
사용자 요청이 발생할 경우 Amazon EC2에 배포한 React에서 요청에 따라 FastAPI(모델 예측값 전달), Springboot(모델 예측 제외 전체)로 값을 요청합니다. 각 백엔드 단에서는 RDS로 데이터를 받아와 각 알고리즘을 적용 후 React로 전달하여 사용자에게 보여줍니다.
RDS에는 크롤링 및 API요청으로 받아와 적재한 또는 사용자의 요청에 의해 발생하는(리뷰, 좋아요) 24개의 table이 존재하며, 그중 분석을 위한 데이터를 S3를 거쳐 Redshift로 전달 후 RDS에는 1주일치 데이터만 남겨두고 삭제합니다. 분석가는 Redshift에 저장된 분석용 데이터와 superset을 사용하여 웹, 모델을 발전시키기 위한 시각화 자료를 만들어줍니다.
3. ERD
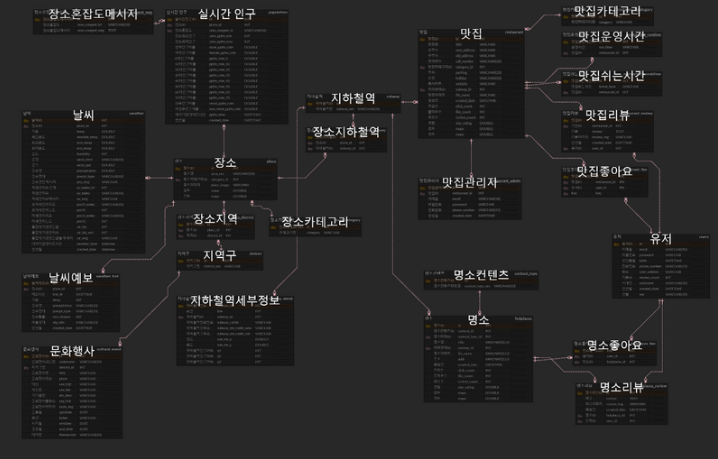
개발 초기에는 위의 ERD보다 덜 복잡한 구조였습니다. 하지만 정규화 과정을 거치며(굉장히 어려운 과정이었습니다.) 테이블이 2배 이상 늘어나게 되었으며 유저 관련 테이블들 또한 다수 생성되었기에 24개의 table로 ERD가 구성되었습니다.
Spring에서 해당 table을 모두 연결하는 과정이 굉장히 어려웠습니다. Spring을 처음 사용하는 입장에서 경험하기에는 확실히 큰 사이즈의 개발이지 않았나 생각합니다. 1주일가량을 ERD에 맞는 백엔드를 구축하기 위해 사용하였고, 그 과정에서 순환참조, DTO의 필요성, Controller, Service, ServiceImpl, JPA Repository, Entity 등의 사용법에 대해 익힐 수 있었습니다. 1주일간의 트러블 슈팅의 결과로 이후의 과정에서는 원래 Java를 사용해 왔던 입장에서 어렵지 않게 개발할 수 있었습니다.
ERD를 작성하며 정규화를 통해 얻게 되는 데이터 중복 방지, 데이터 일관성 유지의 중요성에 대해 알게 되는 시간이었으며, 백엔드단의 편리를 위해 이루어지는 반정규화를 고려해 봤으면 조금 더 좋았지 않았을까 하는 생각도 듭니다.
ERD 외에도 백엔드 단에서는 Log를 Amazon S3로 전송하는데, 이를 가공하여 Amazon Redshift에는 Log관련 테이블이 2개 더 존재합니다.
4. 데이터 수집
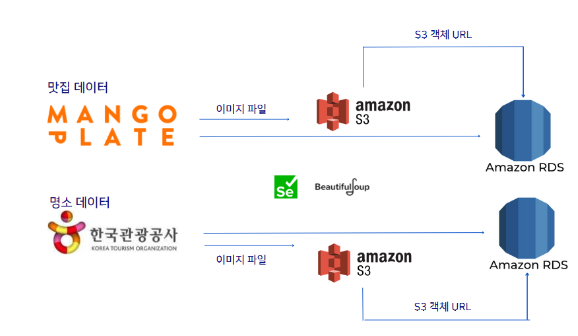
데이터 수집은 상욱님이 전담하여 엔지니어링 파트와 연계하여 RDS에 적재해 주셨습니다. 맛집 데이터의 경우 크롤링을 사용하였으며 명소 데이터는 한국 관광공사 API를 사용하였습니다.
그 외에도 서울시 장소에 대한 정보를 서울시 실시간 도시데이터 API, 기상청 단기예보 API 등에서 데이터를 받아와 RDS에 적재해 주었습니다.
5. 데이터 파이프라인
데이터 파이프라인은 데이터 엔지니어링을 전담하신 상욱님이 전체적으로 담당하셨습니다. 엔지니어링 과정은 아래 상욱님 블로그에 자세히 설명되어 있습니다.
https://dataengineerstudy.tistory.com/196
서울시 혼잡도 데이터를 활용한 안전·문화생활 통합 웹사이트
플레이데이터 최종프로젝트를 마치고 나서 쓰는 회고록입니다. 역할 별로 글을 다 쓰면 너무 길어질 것 같아서, 제 파트 위주로 게시합니다! 더 궁금하신 사항이 있으시다면, 맨 하단에 git 주소
dataengineerstudy.tistory.com
저는 엔지니어링 과정 중에서 분석용 파이프라인 설계에 참여하였습니다. 백엔드 Log관리와 Amazon RDS에 저장한 데이터를 Amazon S3를 거쳐 Amazon Redshift로 Copy 하는 과정이었습니다.

MYSQL RDS에 저장된 데이터를 레드쉬프트로 카피하는 파이프라인입니다.
저희는 데이터 분석을 위해서, 하루에 한 번 간격으로 S3를 거쳐 RDS에서 REDSHIFT로 데이터를 COPY 하는 파이프라인을 설계하였습니다.
또한 RDS 부하를 줄이기 위해 MySQL Event Trigger를 사용하였습니다. 앞서 이야기드렸듯이 redshift와 s3로 데이터를 카피해 두었기 때문에 RDS에서 모든 데이터를 가지고 있을 필요가 없어졌습니다. 그래서 매일 업데이트되는 실시간 혼잡도 테이블과 날씨 테이블에 Event Trigger를 적용하여 웹 제공에 필요한 1주일치 데이터만 남겨두고 자동으로 삭제함으로써 RDS의 부하를 줄여 주었습니다.
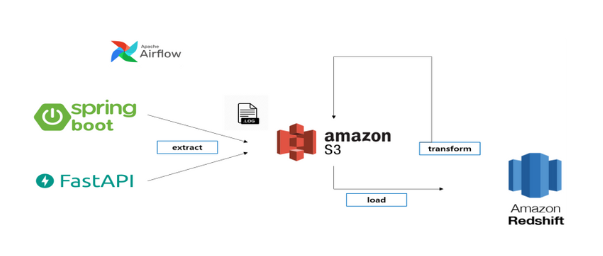
로그 분석 파이프라인 설계입니다.
로그 데이터의 경우 사용자가 웹을 사용하며 남긴 기록을 FASTAPI와 SPRING BOOT의 RestAPI 형태로 AWS s3에 적재할 수 있는 코드를 작성하였습니다. 해당 API 호출을 통해 S3에 원본 데이터를 저장 후 가공하여 REDSHIFT에 적재하는 구조입니다.
Spring 로그의 경우 Slf4j를 사용하여 Controller의 앞단인 Interceptor 단에서 사용자 Request가 들어온 시점, Controller에서 요청이 다 마무리되고, View로 Rendering 하게 전, 후로 나뉘어 로그를 기록하였습니다.
FastAPI의 경우 logging 모듈을 사용하여 api 호출부 내부에서 사용자가 입력한 인자값과, 요청시간, 사용자 데이터를 로그로 기록하였습니다.
해당 데이터들은 데이터웨어하우스에 적재하며, 분석가는 APACHE SUPERSET을 통해서 데이터를 시각화하고 분석합니다.
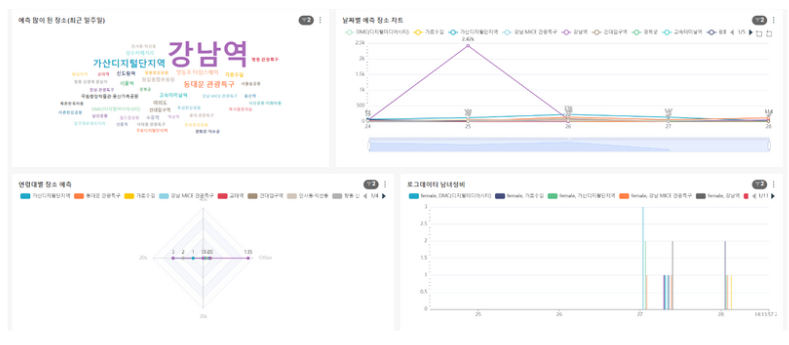
해당 사진이 APACHE SUPERSET을 사용하여 로그 분석을 한 예시입니다.
이렇게 분석용 파이프라인들을 설계한 이유는 이 웹서비스가 지속적으로 운영된다는 가정하에, 새로운 머신러닝 모델과 데이터 분석을 통한 새로운 가치 창출을 위한 목적입니다. 지금 해당 파이프라인들이 지속적으로 가동될 경우, 저희는 새로운 협업 필터링 모델을 통한 개인화된 맛집, 명소 추천 모델, 그리고 더욱더 정교한 장소 추천 모델링이 가능해질 것입니다.
6. 웹 구현

홈페이지입니다. 저희 사이트는 JWT를 기반으로 작동하기 때문에 회원가입이 필수적으로 이루어져야 합니다. 사용자가 시작하기 버튼을 눌러도 로그인이 되어있지 않다면 로그인 창으로 이동하게 됩니다.
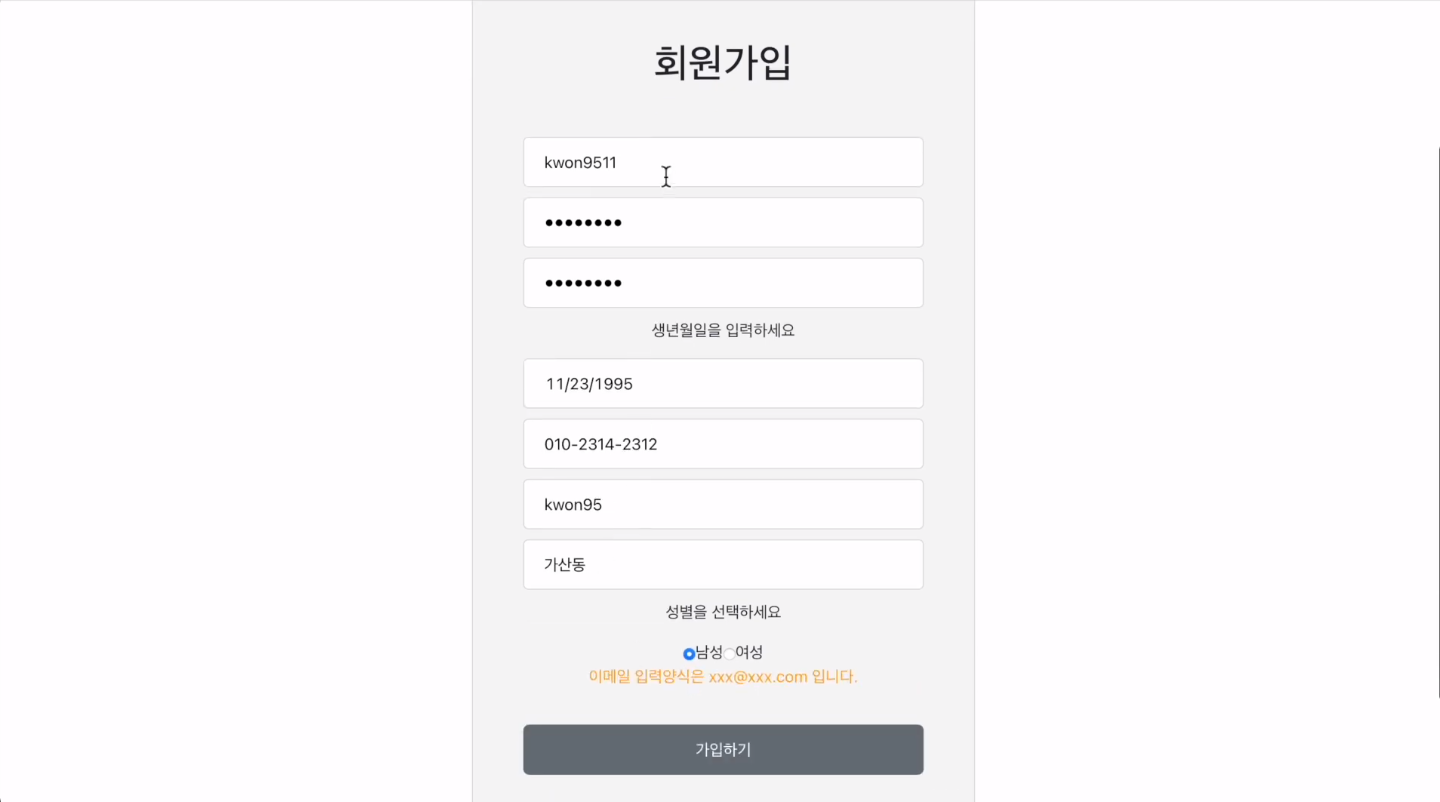
회원가입 양식을 어길 경우 아래 노란 메시지로 validation에 어긋나는 내용을 보여줍니다.
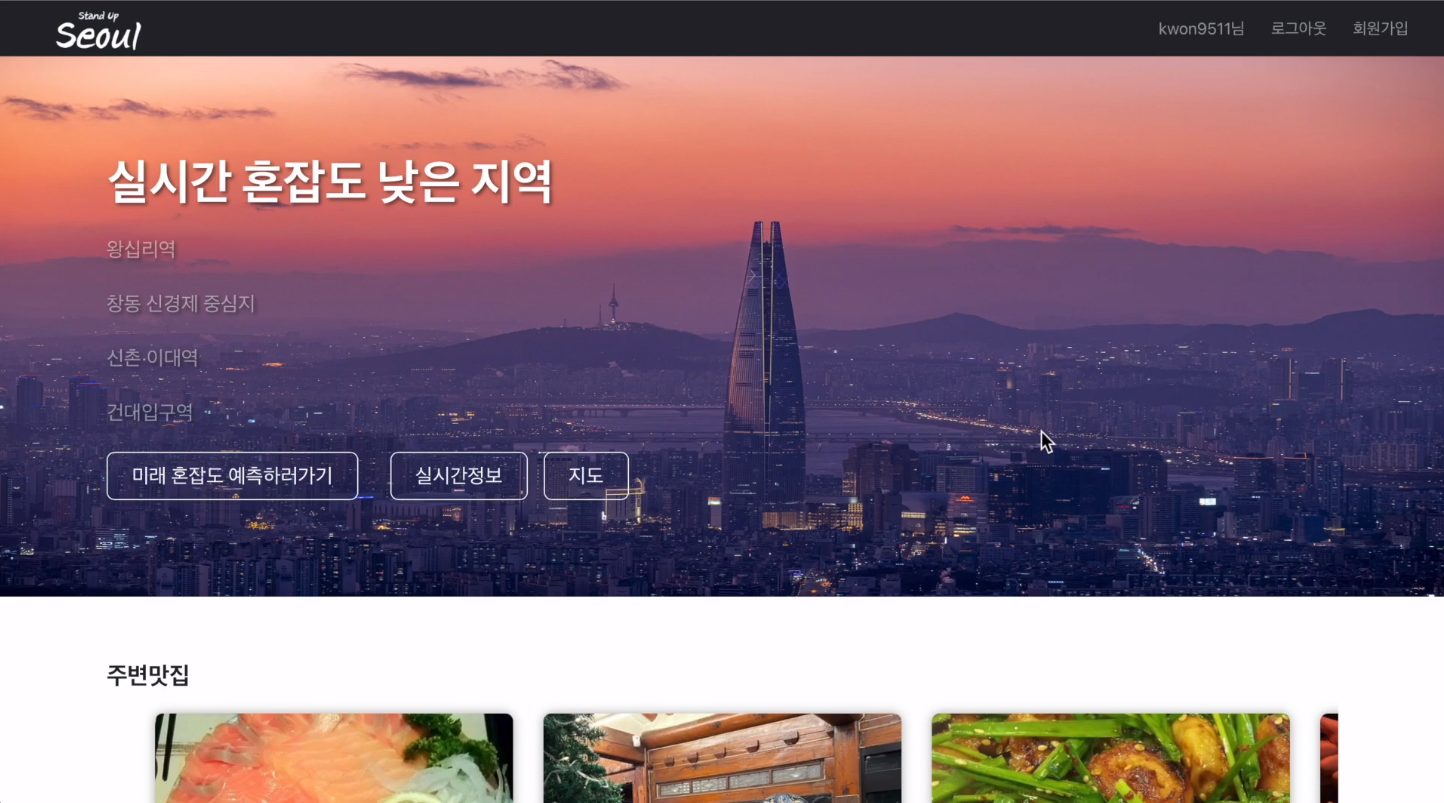
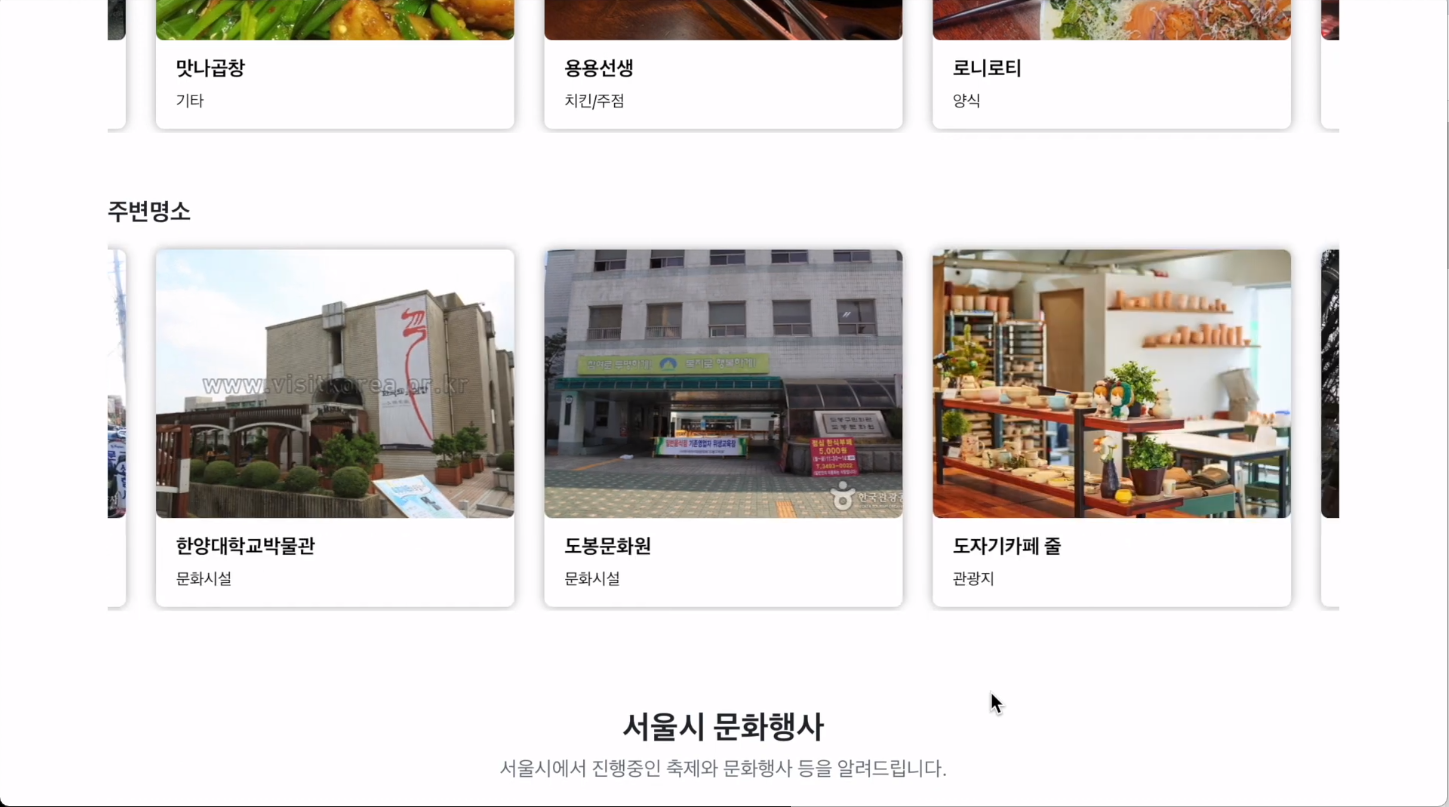
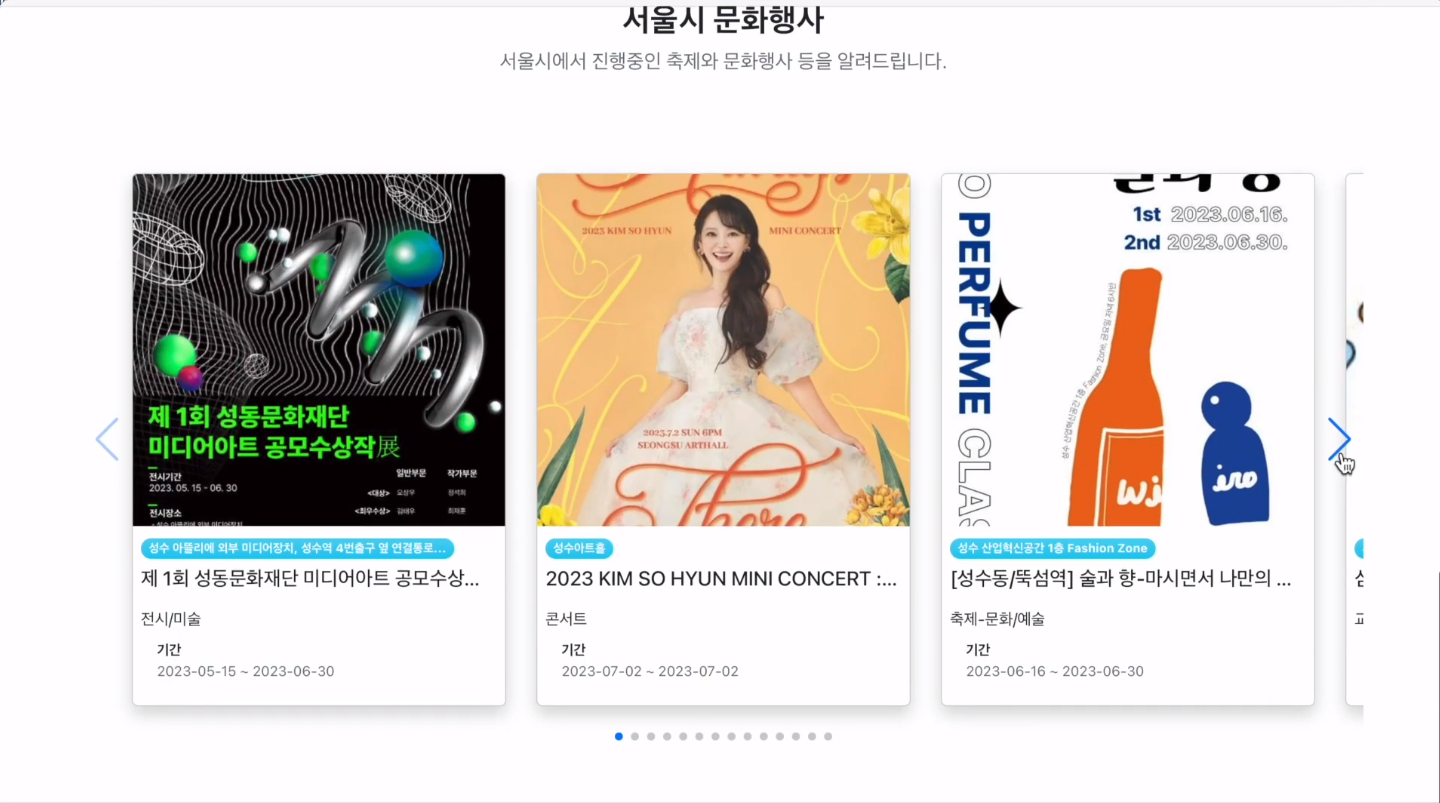
로그인을 수행한 후 시작하기 버튼을 누르게 되면 랜덤기반으로 실시간 여유인 장소를 보여주며 해당 장소 인근의 맛집, 명소, 문화행사를 추천해 줍니다.
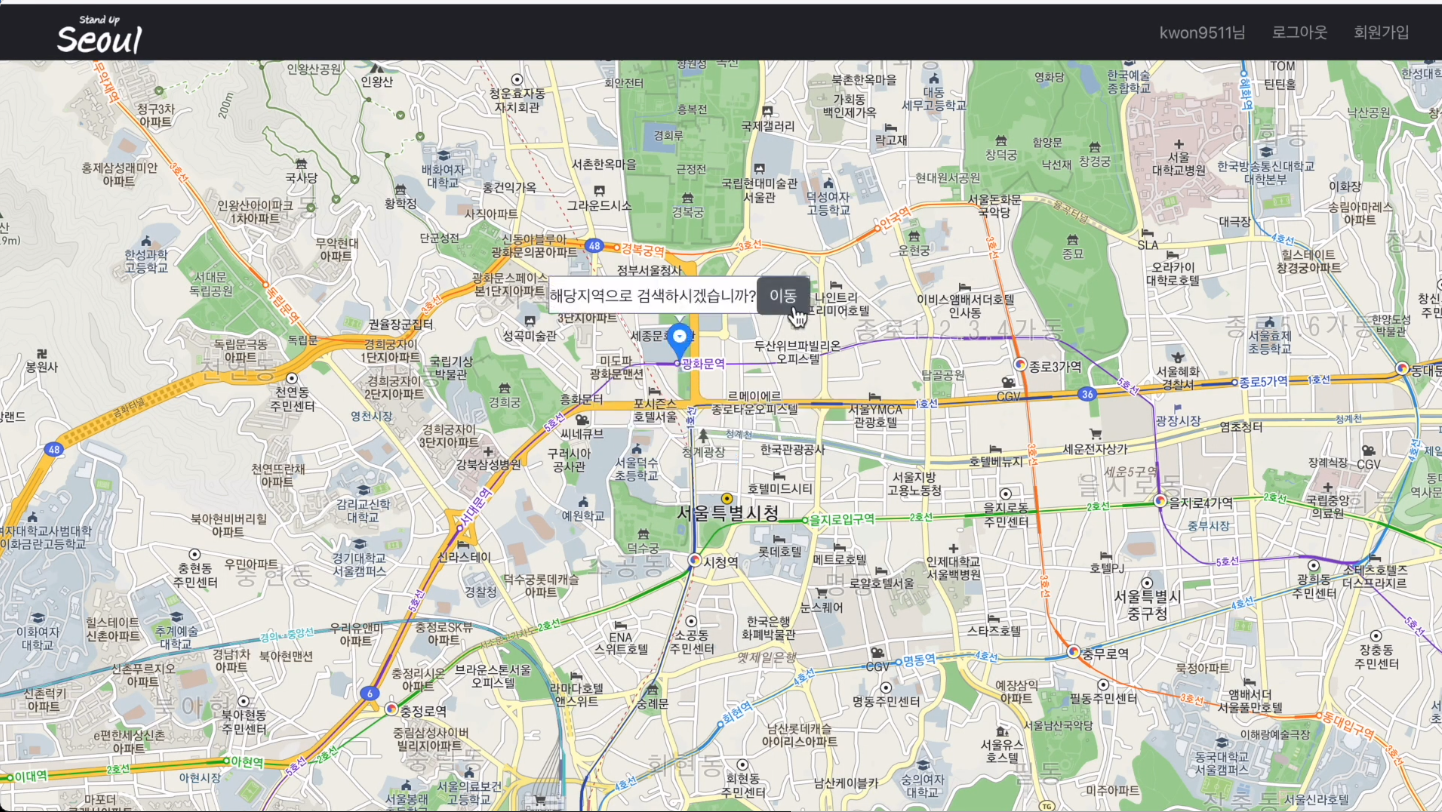

실시간 페이지에서 지도버튼을 클릭하게 되면 사용자가 검색하고 싶은 위치를 선택할 수 있습니다. 사용자가 선택한 장소 인근의 여유로운 장소들을 보여주며, 동일하게 맛집, 명소, 문화행사를 추천해 줍니다.
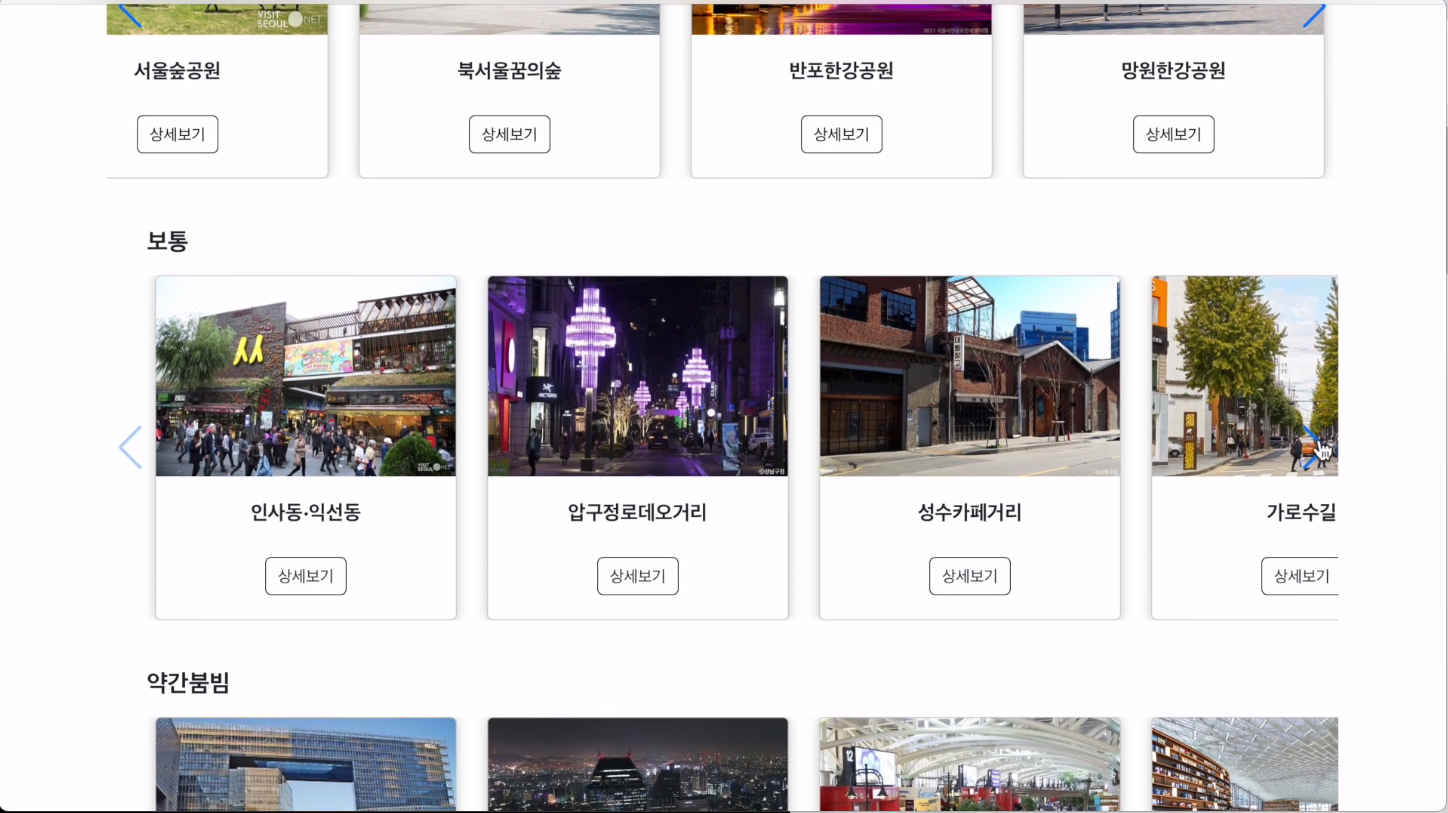
실시간 페이지에서 상세 정보 버튼을 클릭하면 실시간 상세 정보 페이지를 보여줍니다. 해당 페이지는 서울시 혼잡도 데이터를 여유, 보통, 약간 붐빔, 붐빔으로 분류하여 모든 장소에 대한 혼잡도를 보여줍니다.
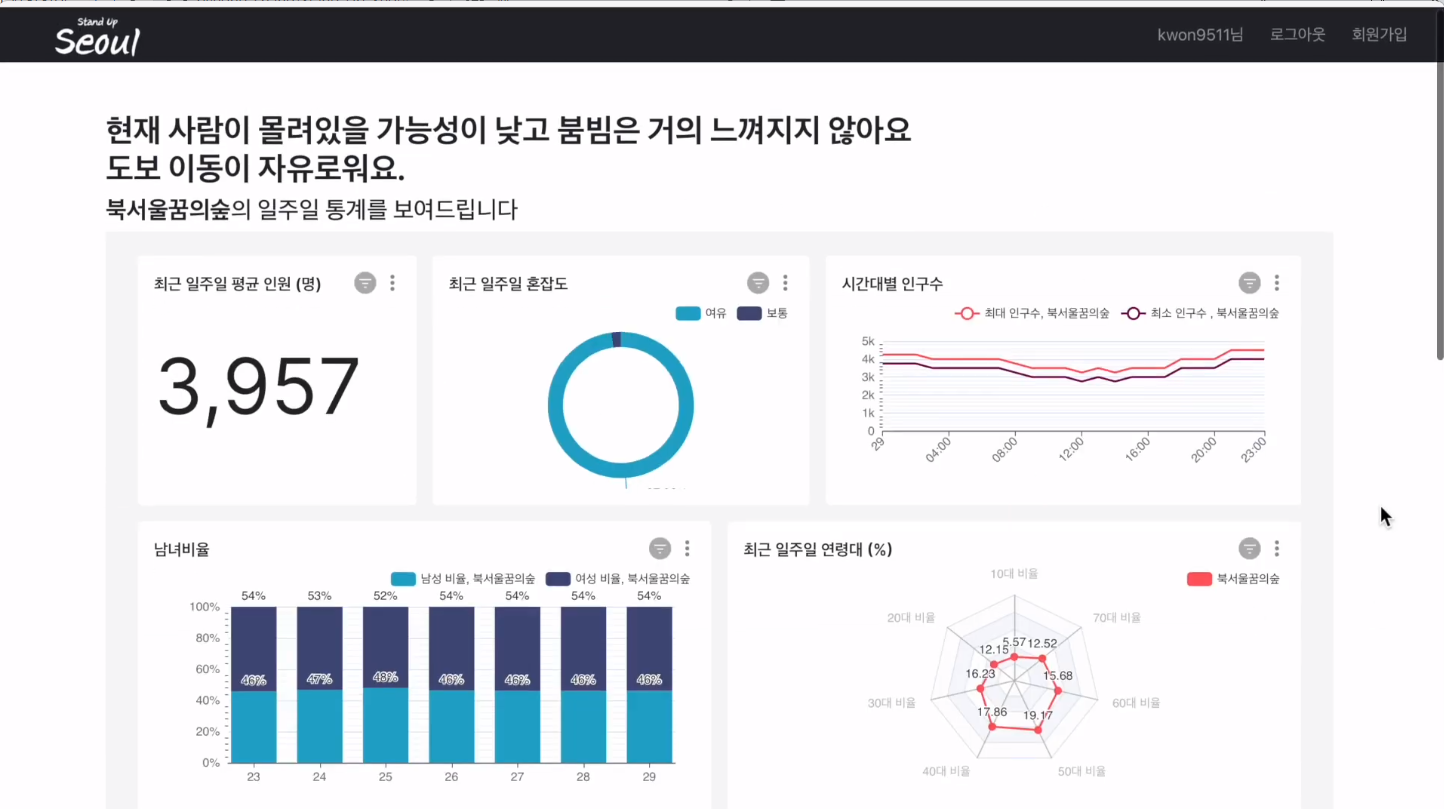
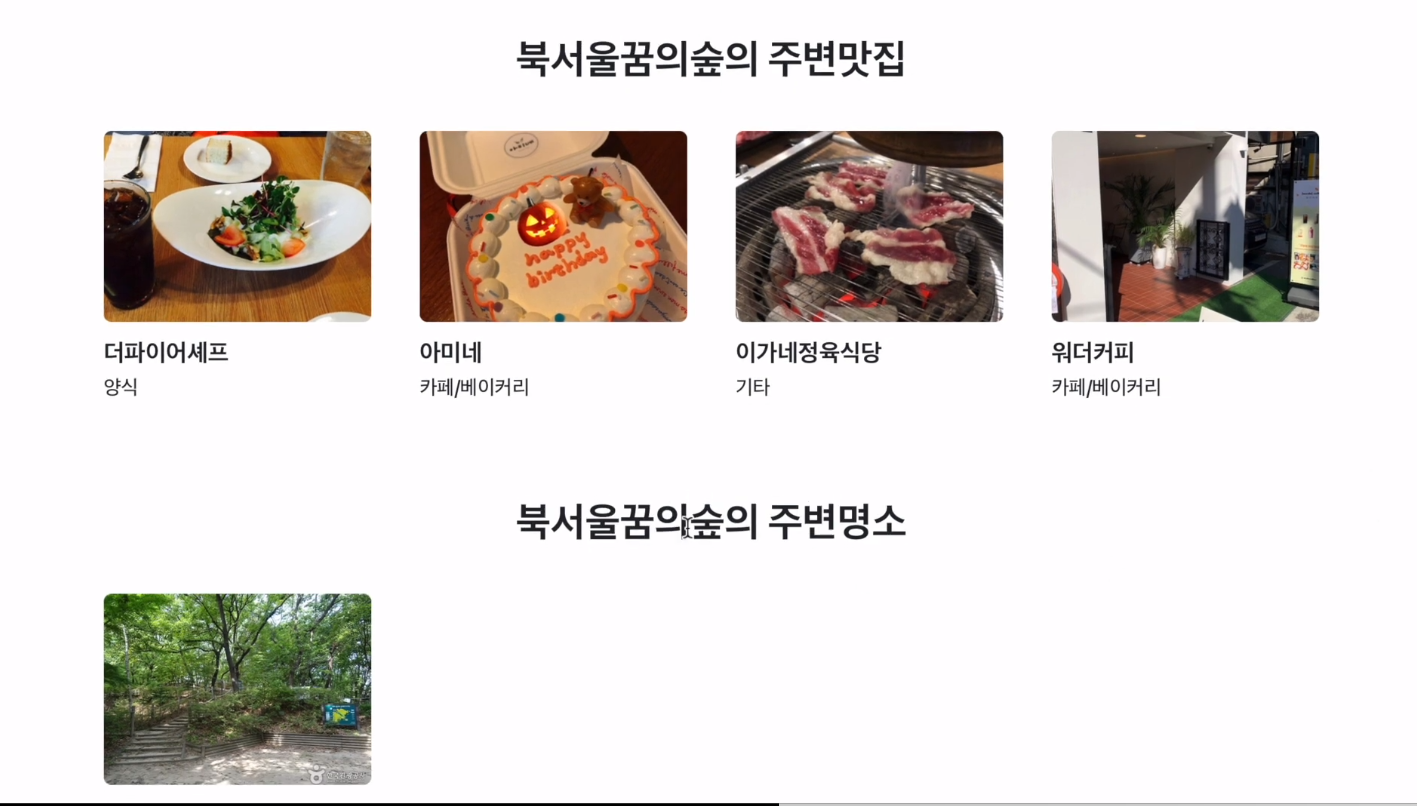
한 장소에 대한 상세 보기를 요청하는 경우 해당 장소에 대한 일주일 통계 superset 대시보드를 제공하고, 해당 장소의 맛집과 명소를 추천해 줍니다.
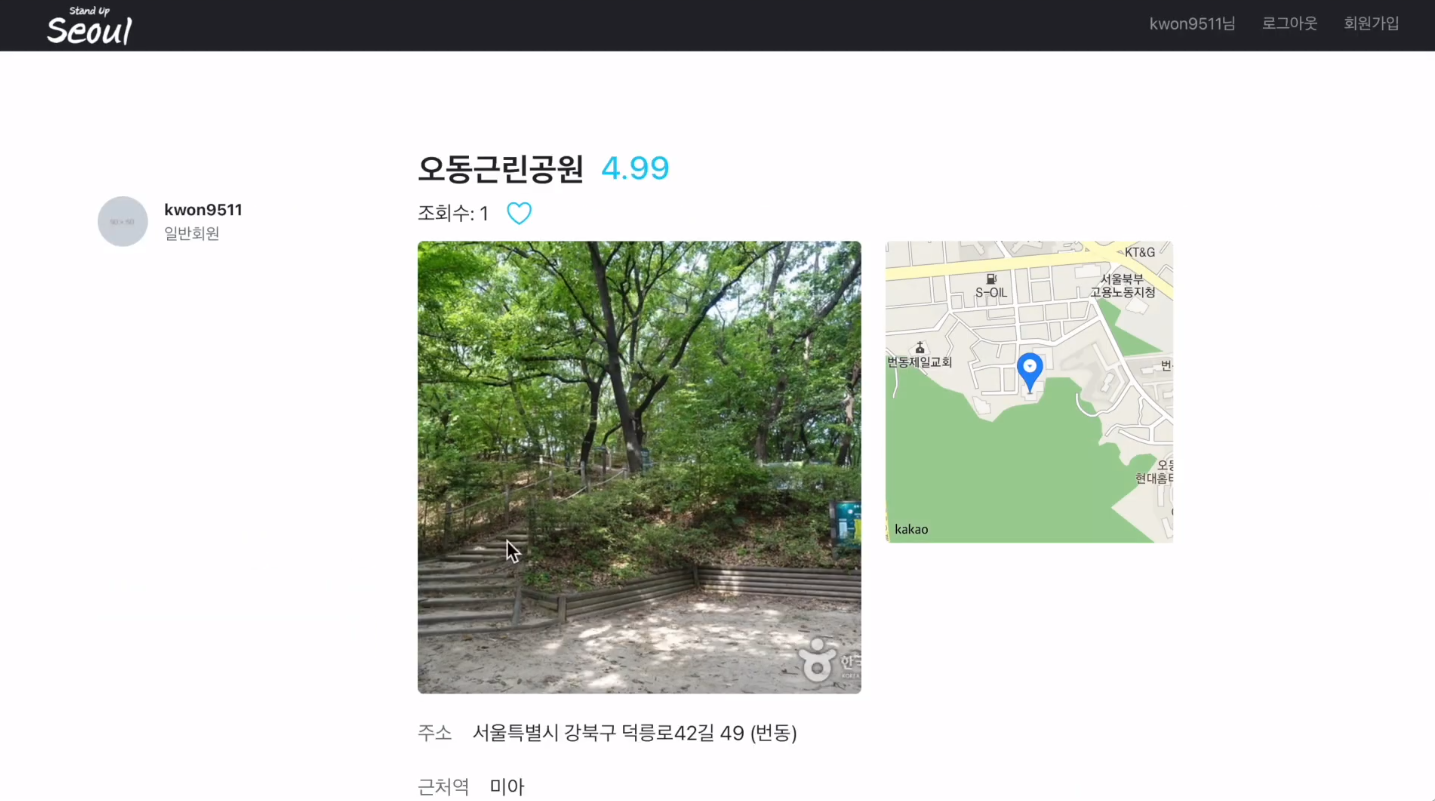
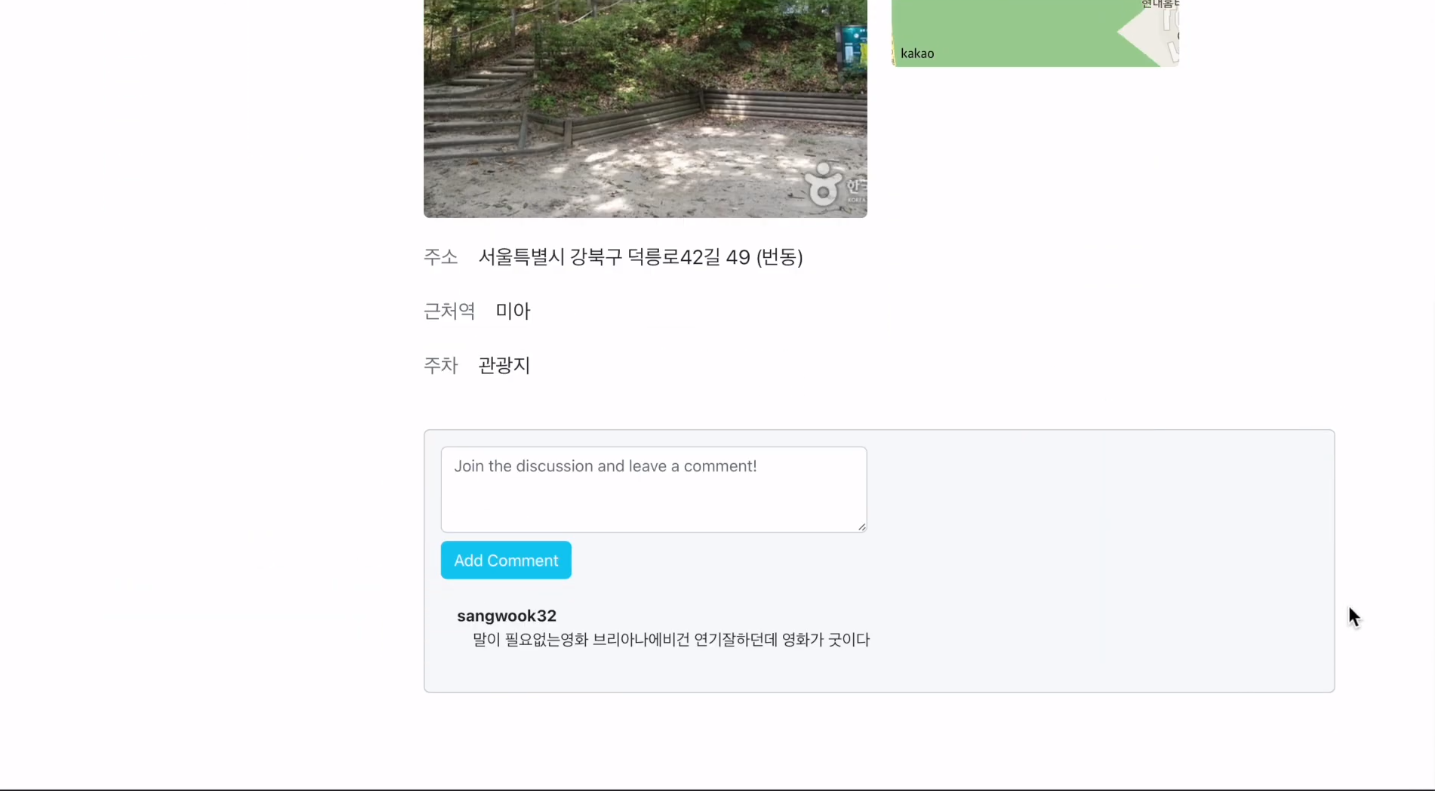
맛집과 명소의 경우 이미지를 클릭할 경우 해당 맛집에 대한 자세한 정보와 댓글을 달아 커뮤니케이션할 수 있는 공간이 주어집니다. 문화행사의 경우 매일 데이터가 변동하기 때문에 댓글은 구현하지 않았고, 문화행사에 대한 자세한 정보를 제공합니다.
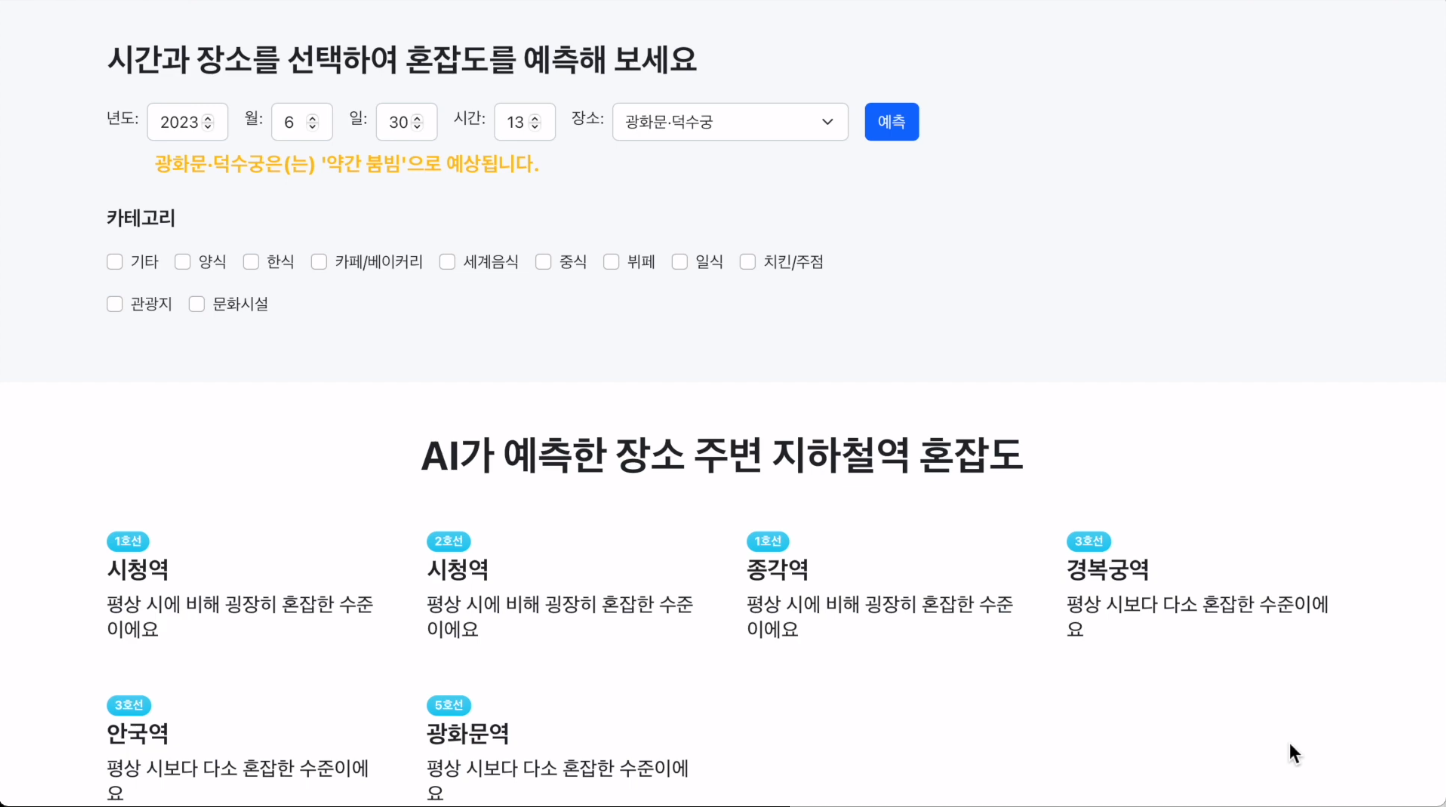
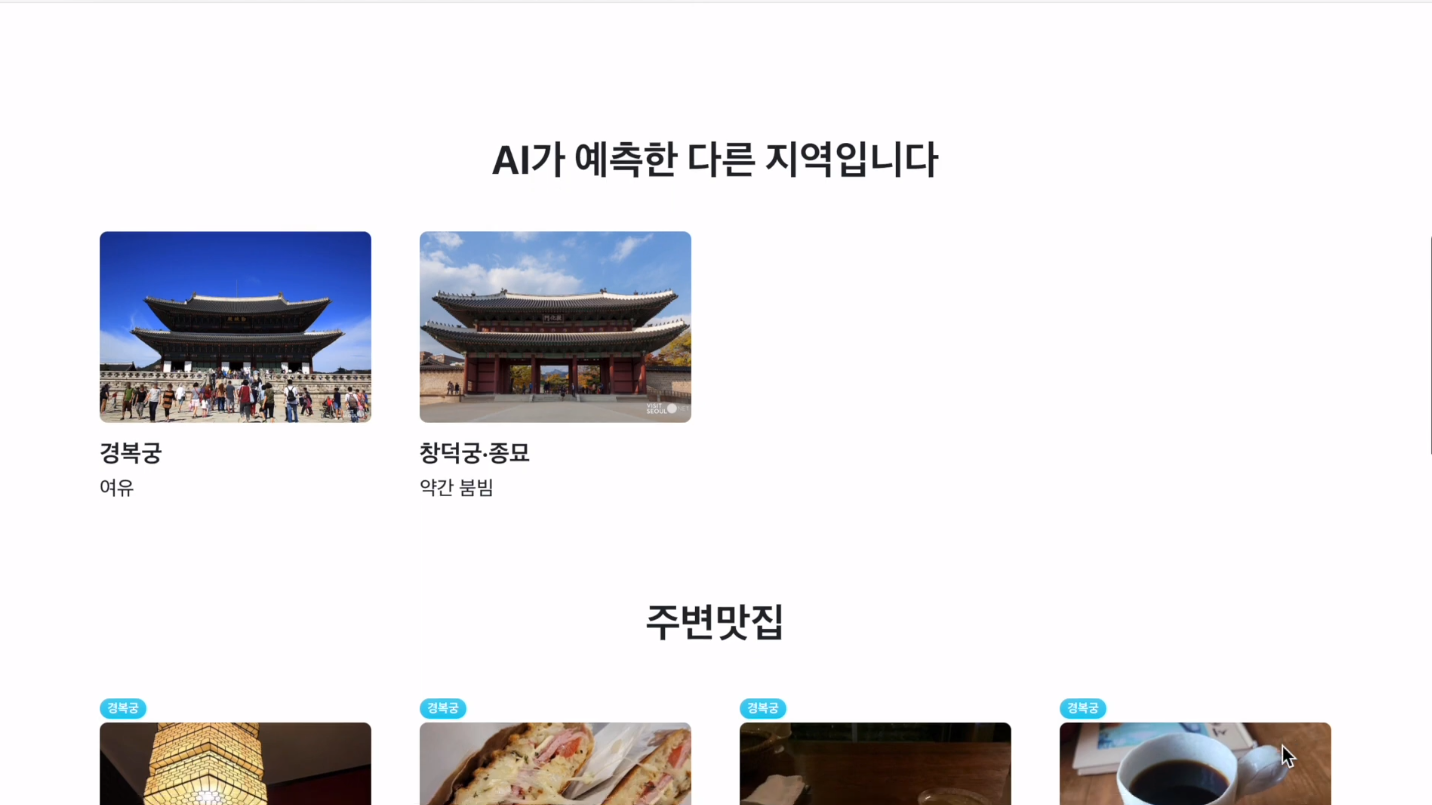
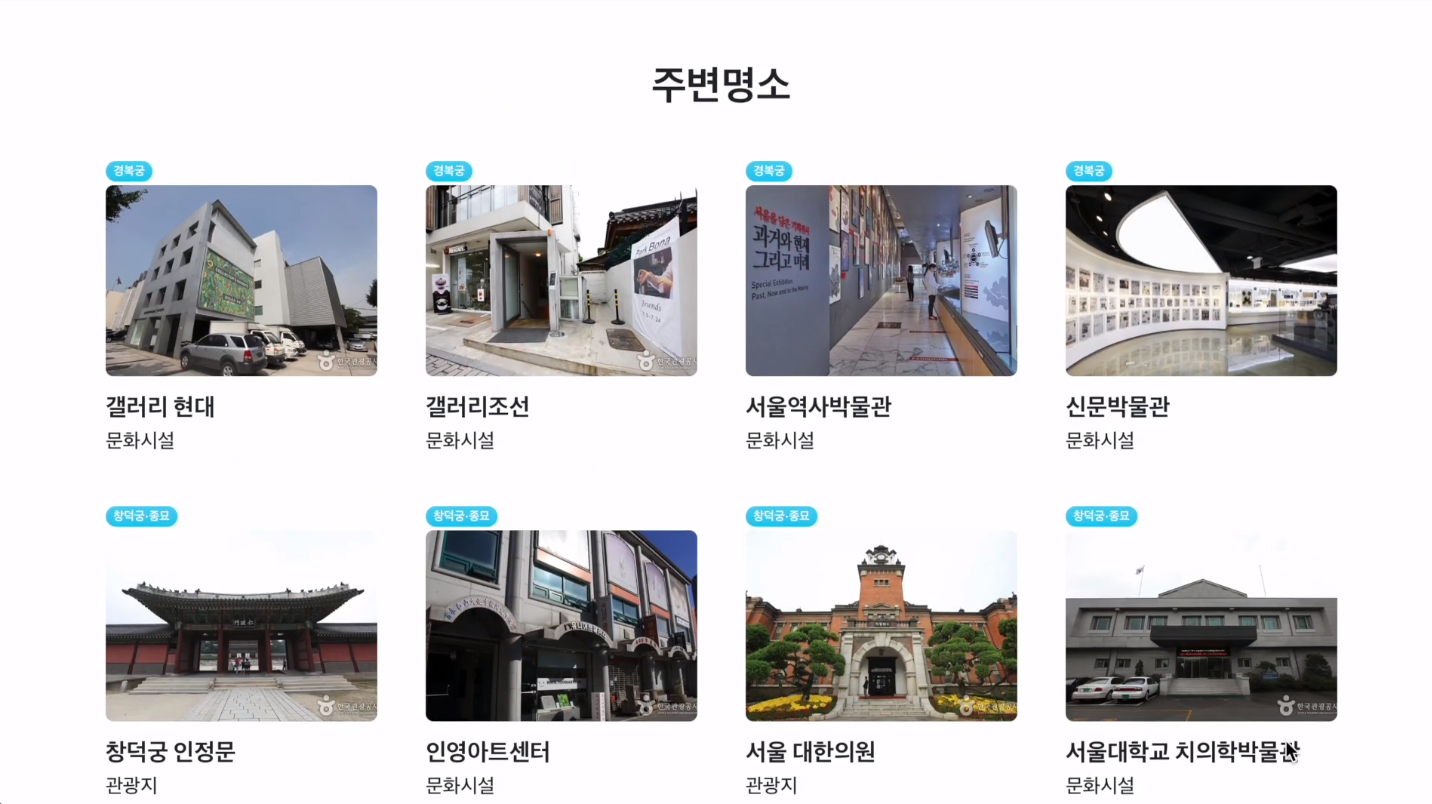
미래 혼잡도 예측 페이지는 시간과 장소를 선택해 주시면 저희의 모델이 예측한 결과와 주변 지하철역 혼잡도를 보여줍니다. 카테고리를 선택하게 되면 선택한 카테고리에 대한 정보만을 보여줍니다.
7. 웹 시연영상
https://www.youtube.com/watch?v=xOqyAW4Hq0Y
8. 느낀 점
좋은 팀원들과 작업할 수 있었던 것이 가장 좋은 점이었다고 생각한다. 밤에 잠을 늦게 자는 것을 못했기에 팀원들과 밤을 함께 새지는 않았지만, 11시에 귀가하여 가볍게 운동 후 5~6시에 일어나 작업하는 생활을 반복했던 것 같다. 프로젝트를 진행하며 피곤함 때문에, 예민해질 수 있었을 텐데 항상 웃으며 작업할 수 있는 팀원들과 함께했기에 즐거웠던 마지막 프로젝트였다.
이번에는 코드를 짜면서 주석을 넣는 게 좀 부족하지 않았나 싶다. spring 코드가 복잡하고 익숙하지 않다 보니 흐름이 끊기지 않기 위해 우선 개발을 하다 보니 주석을 잊게 되었다. 발표 평가해 주신 분이 이야기하시기를 항상 코드 짜기 전에 주석을 미리 작성한 후 그 프로세스에 맞게 코드를 작성하는 방법을 추천해 주셨다. 코드 짜기 전에 항상 종이에 어떤 로직으로 구현할 것인지 정리하는 편인데, 다음에는 주석을 사용하여 코딩할 방식을 정리해 봐야겠다.
마지막 프로젝트이니만큼 이번에는 반드시 Git Commit을 자세히 남겨 봐야겠다는 다짐하에 많은 자료를 찾아봤다. 그중에서 GUI 툴인 GitKraken와 Gihub projects의 칸반보드를 사용한 Issue관리로 커밋을 작성하는 방법에 대해 알게 되었고, 해당 방법을 모든 팀원들이 이해할 수 있게 자료를 작성하여 강의해 줬던 부분이 인상 깊게 남는다. 후에 학교로 돌아가 프로젝트를 하게 되더라도 깃에 대한 두려움은 확실히 없을 것 같다는 성장을 느꼈다.
저희 프로젝트에서 사용한 깃 브랜치 전략에 대해 궁금하시다면 아래 저의 블로그 링크를 가서 읽어보시면 좋을 것 같습니다. https://mbspear.tistory.com/entry/StandUpSeoul-Git-Branch-%EC%A0%84%EB%9E%B5
StandUpSeoul Git Branch 전략
칸반보드를 기준으로 시작합니다. 칸반보드는 시각적 프로젝트 관리의 한 형태입니다. 실무에서 프로젝트 관리 시에 해당 프로젝트에 필요한 기능, 업무들을 정리해 두고, 프로젝트 진행도를
mbspear.tistory.com
웹백 배포에 대한 이해가 부족했던 부분이 아쉽다. 초기 개발단계에서 프론트가 백의 요청을 받아 처리하기 위해서 프론트엔드 개발자인 경목님의 Local PC에 Spring 코드를 실행할 수 있게 해줘야한다고 생각했다. 그래서 Spring안에 React를 설치하는 방식으로 하나로 묶어 처리하게 되었고, 해당 방식을 배포까지 가져가게 되었다....
다음에 프로젝트를 한다면 백엔드 서버를 우선적으로 배포한 후 리엑트에서 해당 EC2 ip로 요청을 보낼 수 있도록 하는 방법을 사용한다면 개발단계에서부터 배포에 최적화된 프론트엔드 구현이 가능했을 것이라는 아쉬움이 남았습니다.
5주라는 긴 시간 동안 함께 힘내서 작업해 줬던 팀원분들께 감사하며, 좋은 기획을 가져와 주시고, 백엔드의 편의를 위해 프로젝트 초반부터 밤을 새워가며 RDS 구축에 힘쓰셨던 우상욱 팀장님께 특히 감사합니다. 정말 많은 걸 배워가는 프로젝트였고, 정리하고 기록하는 습관에 대해 칭찬받았던 기억덕에 앞으로도 항상 자료를 정리하고, 공부한 내용을 블로그에 열심히 업로드해야겠다는 생각을 가지게 되었습니다.
'회고록' 카테고리의 다른 글
| 음성 데이터 처리 하며 느낀점 (0) | 2024.06.27 |
|---|---|
| Neurosense 인턴 회고록 (3) | 2024.03.08 |
| 국비지원 Playdata Encore후기 (0) | 2023.07.03 |
| Django와 Spotify로 노래 추천 웹 개발 - 2 (0) | 2023.07.03 |
| Django와 Spotify로 노래 추천 웹 개발 - 1 (0) | 2023.07.03 |
서울시 혼잡도 기반 장소 추천 프로젝트
- 2023.05.22 ~ 2023.06.30 동안 진행했던 프로젝트입니다. 약 10일 정도는 spring 공부를 위해 시간을 사용했으며, Backend 개발에 사용한 시간은 4주입니다. Playdata Encore에서 진행한 마지막 프로젝트이며, 제가 담당한 역할은 Backend입니다.
- github : https://github.com/byeong-chang/Stand_Up_Seoul
GitHub - byeong-chang/Stand_Up_Seoul: Playdata final project - 서울시 지하철 데이터를 사용하여 혼잡도를 분석
Playdata final project - 서울시 지하철 데이터를 사용하여 혼잡도를 분석하여 서비스 제공 - GitHub - byeong-chang/Stand_Up_Seoul: Playdata final project - 서울시 지하철 데이터를 사용하여 혼잡도를 분석하여 서
github.com
1. 프로젝트 소개
1) 팀원별 역할
우상욱(팀장) : 데이터엔지니어링
(1) 데이터베이스 설계 및 구축
(2) 맛집, 명소 데이터 크롤링
(3) Airflow 활용 운영 데이터 파이프라인 설계 및 구축
(4) Aws Lambda 활용, 딥러닝 모델(Tensorflow)을 활용한 별점 업데이트 파이프라인 설계 및 구축
(5) 데이터웨어하우스 설계 및 구축(Aws Redshift)
(6) Superset 데이터 시각화 서버 구축 및 DB, DW 연동
(7) 머신러닝 API 서버 구현(FastAPI)
(8) Airflow 활용 ML 모델 자동화 배포 파이프라인 설계 및 구현
(9) 로그 데이터 수집 및 가공 파이프라인 설계
(10) 발표
김호영 : 데이터분석, 머신러닝
(1) 데이터 가공/전처리/시각화
(2) 지하철 승하차 인원, 장소 혼잡도 모델 설계 및 구축
(3) Aws Lambda 활용, 딥러닝(Tensorflow) 모델을 활용한 별점 업데이트 파이프라인 설계 및 구축
(4) 대시보드 구축 및 데이터 분석(Superset)
(5) 머신러닝 API 서버 구현(FastAPI)
(6) 웹 사이트 로그 데이터 가공 및 분석
민병창 : 백엔드
(1) 데이터베이스 설계 및 연동
(2) Mysql Trigger, Event Trigger 작성
(3) Spring Boot와 JWT를 활용한 회원가입/로그인 구현
(4) Spring Boot Interceptor request 로그 데이터 수집 api 구현
(5) Fast api loggers를 활용한 로그 데이터 수집 api 구현
(6) Fast api model 예측값 전달 API 개발
(7) 실시간 지도 기반 추천 알고리즘 개발
(8) AWS EC2를 활용한 spring, react 연동 및 배포
(9) AWS IAM을 사용한 spring, s3 통신 구현
(10) Git repository개설 및 Git branch 전략 설정
(11) 문서정리 ,자료정리, 서기 및 발표
김민수 : 백엔드
(1) Spring Boot와 React 개발환경 설정
(2) Spring Boot를 활용한 실시간 혼잡도 api 구현
(3) Spring Boot를 활용한 실시간 혼잡도 장소 api 구현
(4) Spring Boot를 활용한 사용자 마이페이지 api 구현
(5) AWS EC2를 활용한 spring, react 연동 및 배포
(6) Git repository개설 및 Git branch 전략 설정
김경목 : 프론트엔드
(1) 웹 디자인 설계 및 구현
(2) 사용자 인터페이스 개발
(3) 웹 애플리케이션 개발 환경 설정
(4) Responsiveness(반응형) 개발
(5) UI/UX 개선
(6) 프론트엔드 프레임워크와 라이브러리 활용
(7) 테스팅과 디버깅
2) 사용 기술
- 아래 기술표는 저희 프로젝트에 사용된 기술입니다.
2. 시스템 구성도
사용자 요청이 발생할 경우 Amazon EC2에 배포한 React에서 요청에 따라 FastAPI(모델 예측값 전달), Springboot(모델 예측 제외 전체)로 값을 요청합니다. 각 백엔드 단에서는 RDS로 데이터를 받아와 각 알고리즘을 적용 후 React로 전달하여 사용자에게 보여줍니다.
RDS에는 크롤링 및 API요청으로 받아와 적재한 또는 사용자의 요청에 의해 발생하는(리뷰, 좋아요) 24개의 table이 존재하며, 그중 분석을 위한 데이터를 S3를 거쳐 Redshift로 전달 후 RDS에는 1주일치 데이터만 남겨두고 삭제합니다. 분석가는 Redshift에 저장된 분석용 데이터와 superset을 사용하여 웹, 모델을 발전시키기 위한 시각화 자료를 만들어줍니다.
3. ERD
개발 초기에는 위의 ERD보다 덜 복잡한 구조였습니다. 하지만 정규화 과정을 거치며(굉장히 어려운 과정이었습니다.) 테이블이 2배 이상 늘어나게 되었으며 유저 관련 테이블들 또한 다수 생성되었기에 24개의 table로 ERD가 구성되었습니다.
Spring에서 해당 table을 모두 연결하는 과정이 굉장히 어려웠습니다. Spring을 처음 사용하는 입장에서 경험하기에는 확실히 큰 사이즈의 개발이지 않았나 생각합니다. 1주일가량을 ERD에 맞는 백엔드를 구축하기 위해 사용하였고, 그 과정에서 순환참조, DTO의 필요성, Controller, Service, ServiceImpl, JPA Repository, Entity 등의 사용법에 대해 익힐 수 있었습니다. 1주일간의 트러블 슈팅의 결과로 이후의 과정에서는 원래 Java를 사용해 왔던 입장에서 어렵지 않게 개발할 수 있었습니다.
ERD를 작성하며 정규화를 통해 얻게 되는 데이터 중복 방지, 데이터 일관성 유지의 중요성에 대해 알게 되는 시간이었으며, 백엔드단의 편리를 위해 이루어지는 반정규화를 고려해 봤으면 조금 더 좋았지 않았을까 하는 생각도 듭니다.
ERD 외에도 백엔드 단에서는 Log를 Amazon S3로 전송하는데, 이를 가공하여 Amazon Redshift에는 Log관련 테이블이 2개 더 존재합니다.
4. 데이터 수집
데이터 수집은 상욱님이 전담하여 엔지니어링 파트와 연계하여 RDS에 적재해 주셨습니다. 맛집 데이터의 경우 크롤링을 사용하였으며 명소 데이터는 한국 관광공사 API를 사용하였습니다.
그 외에도 서울시 장소에 대한 정보를 서울시 실시간 도시데이터 API, 기상청 단기예보 API 등에서 데이터를 받아와 RDS에 적재해 주었습니다.
5. 데이터 파이프라인
데이터 파이프라인은 데이터 엔지니어링을 전담하신 상욱님이 전체적으로 담당하셨습니다. 엔지니어링 과정은 아래 상욱님 블로그에 자세히 설명되어 있습니다.
https://dataengineerstudy.tistory.com/196
서울시 혼잡도 데이터를 활용한 안전·문화생활 통합 웹사이트
플레이데이터 최종프로젝트를 마치고 나서 쓰는 회고록입니다. 역할 별로 글을 다 쓰면 너무 길어질 것 같아서, 제 파트 위주로 게시합니다! 더 궁금하신 사항이 있으시다면, 맨 하단에 git 주소
dataengineerstudy.tistory.com
저는 엔지니어링 과정 중에서 분석용 파이프라인 설계에 참여하였습니다. 백엔드 Log관리와 Amazon RDS에 저장한 데이터를 Amazon S3를 거쳐 Amazon Redshift로 Copy 하는 과정이었습니다.
MYSQL RDS에 저장된 데이터를 레드쉬프트로 카피하는 파이프라인입니다.
저희는 데이터 분석을 위해서, 하루에 한 번 간격으로 S3를 거쳐 RDS에서 REDSHIFT로 데이터를 COPY 하는 파이프라인을 설계하였습니다.
또한 RDS 부하를 줄이기 위해 MySQL Event Trigger를 사용하였습니다. 앞서 이야기드렸듯이 redshift와 s3로 데이터를 카피해 두었기 때문에 RDS에서 모든 데이터를 가지고 있을 필요가 없어졌습니다. 그래서 매일 업데이트되는 실시간 혼잡도 테이블과 날씨 테이블에 Event Trigger를 적용하여 웹 제공에 필요한 1주일치 데이터만 남겨두고 자동으로 삭제함으로써 RDS의 부하를 줄여 주었습니다.
로그 분석 파이프라인 설계입니다.
로그 데이터의 경우 사용자가 웹을 사용하며 남긴 기록을 FASTAPI와 SPRING BOOT의 RestAPI 형태로 AWS s3에 적재할 수 있는 코드를 작성하였습니다. 해당 API 호출을 통해 S3에 원본 데이터를 저장 후 가공하여 REDSHIFT에 적재하는 구조입니다.
Spring 로그의 경우 Slf4j를 사용하여 Controller의 앞단인 Interceptor 단에서 사용자 Request가 들어온 시점, Controller에서 요청이 다 마무리되고, View로 Rendering 하게 전, 후로 나뉘어 로그를 기록하였습니다.
FastAPI의 경우 logging 모듈을 사용하여 api 호출부 내부에서 사용자가 입력한 인자값과, 요청시간, 사용자 데이터를 로그로 기록하였습니다.
해당 데이터들은 데이터웨어하우스에 적재하며, 분석가는 APACHE SUPERSET을 통해서 데이터를 시각화하고 분석합니다.
해당 사진이 APACHE SUPERSET을 사용하여 로그 분석을 한 예시입니다.
이렇게 분석용 파이프라인들을 설계한 이유는 이 웹서비스가 지속적으로 운영된다는 가정하에, 새로운 머신러닝 모델과 데이터 분석을 통한 새로운 가치 창출을 위한 목적입니다. 지금 해당 파이프라인들이 지속적으로 가동될 경우, 저희는 새로운 협업 필터링 모델을 통한 개인화된 맛집, 명소 추천 모델, 그리고 더욱더 정교한 장소 추천 모델링이 가능해질 것입니다.
6. 웹 구현
홈페이지입니다. 저희 사이트는 JWT를 기반으로 작동하기 때문에 회원가입이 필수적으로 이루어져야 합니다. 사용자가 시작하기 버튼을 눌러도 로그인이 되어있지 않다면 로그인 창으로 이동하게 됩니다.
회원가입 양식을 어길 경우 아래 노란 메시지로 validation에 어긋나는 내용을 보여줍니다.
로그인을 수행한 후 시작하기 버튼을 누르게 되면 랜덤기반으로 실시간 여유인 장소를 보여주며 해당 장소 인근의 맛집, 명소, 문화행사를 추천해 줍니다.
실시간 페이지에서 지도버튼을 클릭하게 되면 사용자가 검색하고 싶은 위치를 선택할 수 있습니다. 사용자가 선택한 장소 인근의 여유로운 장소들을 보여주며, 동일하게 맛집, 명소, 문화행사를 추천해 줍니다.
실시간 페이지에서 상세 정보 버튼을 클릭하면 실시간 상세 정보 페이지를 보여줍니다. 해당 페이지는 서울시 혼잡도 데이터를 여유, 보통, 약간 붐빔, 붐빔으로 분류하여 모든 장소에 대한 혼잡도를 보여줍니다.
한 장소에 대한 상세 보기를 요청하는 경우 해당 장소에 대한 일주일 통계 superset 대시보드를 제공하고, 해당 장소의 맛집과 명소를 추천해 줍니다.
맛집과 명소의 경우 이미지를 클릭할 경우 해당 맛집에 대한 자세한 정보와 댓글을 달아 커뮤니케이션할 수 있는 공간이 주어집니다. 문화행사의 경우 매일 데이터가 변동하기 때문에 댓글은 구현하지 않았고, 문화행사에 대한 자세한 정보를 제공합니다.
미래 혼잡도 예측 페이지는 시간과 장소를 선택해 주시면 저희의 모델이 예측한 결과와 주변 지하철역 혼잡도를 보여줍니다. 카테고리를 선택하게 되면 선택한 카테고리에 대한 정보만을 보여줍니다.
7. 웹 시연영상
https://www.youtube.com/watch?v=xOqyAW4Hq0Y
8. 느낀 점
좋은 팀원들과 작업할 수 있었던 것이 가장 좋은 점이었다고 생각한다. 밤에 잠을 늦게 자는 것을 못했기에 팀원들과 밤을 함께 새지는 않았지만, 11시에 귀가하여 가볍게 운동 후 5~6시에 일어나 작업하는 생활을 반복했던 것 같다. 프로젝트를 진행하며 피곤함 때문에, 예민해질 수 있었을 텐데 항상 웃으며 작업할 수 있는 팀원들과 함께했기에 즐거웠던 마지막 프로젝트였다.
이번에는 코드를 짜면서 주석을 넣는 게 좀 부족하지 않았나 싶다. spring 코드가 복잡하고 익숙하지 않다 보니 흐름이 끊기지 않기 위해 우선 개발을 하다 보니 주석을 잊게 되었다. 발표 평가해 주신 분이 이야기하시기를 항상 코드 짜기 전에 주석을 미리 작성한 후 그 프로세스에 맞게 코드를 작성하는 방법을 추천해 주셨다. 코드 짜기 전에 항상 종이에 어떤 로직으로 구현할 것인지 정리하는 편인데, 다음에는 주석을 사용하여 코딩할 방식을 정리해 봐야겠다.
마지막 프로젝트이니만큼 이번에는 반드시 Git Commit을 자세히 남겨 봐야겠다는 다짐하에 많은 자료를 찾아봤다. 그중에서 GUI 툴인 GitKraken와 Gihub projects의 칸반보드를 사용한 Issue관리로 커밋을 작성하는 방법에 대해 알게 되었고, 해당 방법을 모든 팀원들이 이해할 수 있게 자료를 작성하여 강의해 줬던 부분이 인상 깊게 남는다. 후에 학교로 돌아가 프로젝트를 하게 되더라도 깃에 대한 두려움은 확실히 없을 것 같다는 성장을 느꼈다.
저희 프로젝트에서 사용한 깃 브랜치 전략에 대해 궁금하시다면 아래 저의 블로그 링크를 가서 읽어보시면 좋을 것 같습니다. https://mbspear.tistory.com/entry/StandUpSeoul-Git-Branch-%EC%A0%84%EB%9E%B5
StandUpSeoul Git Branch 전략
칸반보드를 기준으로 시작합니다. 칸반보드는 시각적 프로젝트 관리의 한 형태입니다. 실무에서 프로젝트 관리 시에 해당 프로젝트에 필요한 기능, 업무들을 정리해 두고, 프로젝트 진행도를
mbspear.tistory.com
웹백 배포에 대한 이해가 부족했던 부분이 아쉽다. 초기 개발단계에서 프론트가 백의 요청을 받아 처리하기 위해서 프론트엔드 개발자인 경목님의 Local PC에 Spring 코드를 실행할 수 있게 해줘야한다고 생각했다. 그래서 Spring안에 React를 설치하는 방식으로 하나로 묶어 처리하게 되었고, 해당 방식을 배포까지 가져가게 되었다....
다음에 프로젝트를 한다면 백엔드 서버를 우선적으로 배포한 후 리엑트에서 해당 EC2 ip로 요청을 보낼 수 있도록 하는 방법을 사용한다면 개발단계에서부터 배포에 최적화된 프론트엔드 구현이 가능했을 것이라는 아쉬움이 남았습니다.
5주라는 긴 시간 동안 함께 힘내서 작업해 줬던 팀원분들께 감사하며, 좋은 기획을 가져와 주시고, 백엔드의 편의를 위해 프로젝트 초반부터 밤을 새워가며 RDS 구축에 힘쓰셨던 우상욱 팀장님께 특히 감사합니다. 정말 많은 걸 배워가는 프로젝트였고, 정리하고 기록하는 습관에 대해 칭찬받았던 기억덕에 앞으로도 항상 자료를 정리하고, 공부한 내용을 블로그에 열심히 업로드해야겠다는 생각을 가지게 되었습니다.
'회고록' 카테고리의 다른 글
| 음성 데이터 처리 하며 느낀점 (0) | 2024.06.27 |
|---|---|
| Neurosense 인턴 회고록 (3) | 2024.03.08 |
| 국비지원 Playdata Encore후기 (0) | 2023.07.03 |
| Django와 Spotify로 노래 추천 웹 개발 - 2 (0) | 2023.07.03 |
| Django와 Spotify로 노래 추천 웹 개발 - 1 (0) | 2023.07.03 |