
데이터베이스란?
데이터베이스
- 여러 살마에 의해 특정 분야에서 사용될 목적으로 통합하여 관리되는 데이터의 집합체
- 다수의 사용자가 사용하는 데이터들의 공유와 운영을 위해 저장해 놓은 공간으로 자료항목의 중복성을 없애 줌
- 자료를 구조화하여 저장함으로써 데이터 검색과 업데이트의 효율성을 높여 줌
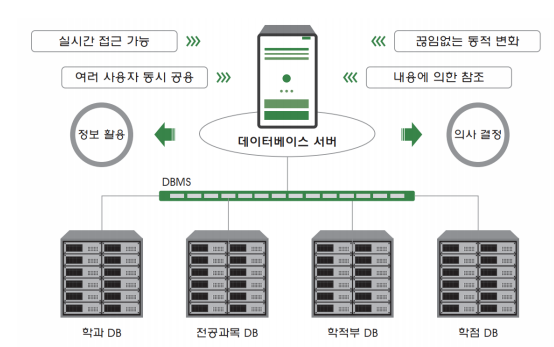
DBMS
- 데이터베이스 관리 시스템(DBMS)이란 데이터베이스를 직접 응용 프로그램들이 조작하는 것이 아니라
- 데이터베이스를 조작하는 별도의 소프트웨어를 의미하며 앞으로 사용하게 될 MySQL 또한 DBMS의 한 종류임
MySQL
- RDBMS 중 하나로 오픈 소스 라이브러리 정책에 따라 배포됨
- 영리목적일 경우 라이선스 구매 필요
- MySQL은 오픈 소스이며 다중 사용자와 다중 스레드를 제공하며 다음과 같은 장점을 제공
- MySQL 응용 프로그램을 개발자의 용도에 맞게 수정이 용이
- 다양한 운영체제에서 사용할 수 있으며 여러 종류의 프로그래밍 언어 지원
- 표준 SQL 형식을 지원
외래키는 1쪽에 있는걸 N 쪽에 넣어줘야 함
SQL : Structured Query Language
- 관계형 데이터베이스 관리 시스템의 데이터를 관리하기 위해 설계된 특수 목적의 프로그래밍 언어
- SQL 쿼리문은 데이터베이스에 저장된 값을 불러내기 위한 명령문
- 데이터베이스 관련 명령어와 테이블 관련 명령어로 구분되어 수행
- 일부 명령어를 제외하고 나머지 명령어에 대한 알파벳 대/소문자를 특별히 구분하지 않음.
use
- 생성되어 있는 데이터베이스를 선택할 때 사용
use 데이터베이스명;인덱스
- 데이터를 빠르게 찾기 위해 만듬
- 내가 검색하고자 하는 것이 많지 않을 때만 효율이 좋다. 찾을게 많다면 목차를 볼 필요 없이 전체 데이터를 읽어내는 것이 더 빠를 수 있다.
- 이를 결정하기 위해서는 데이터의 분포도를 확인하여 결정해야 한다.
- 데이터 분포도가 작으면서 WHERE 조건절에 많이 언급되는 column들에 index를 넣어주는 것이 좋다.
create index idx_test on product(id,prices);- 위 코드와 같이 2개 이상의 column에 대한 결합 인덱스도 존재한다.
- 유지관리에 추가적인 비용이 발생한다.
데이터 검색 방법
- 선형 탐색
- Binary Tree
- B-tree : 자식 노드를 binary가 아니라 balance 하게 여러 노드를 가질 수 있게 하는 트리구조(가장 많이 쓰이는 index 자료구조)
- b+ tree : b-tree보다 갱신에 대해 더 효율적인 방식
데이터 타입
- 실제 데이터를 저장하기 위해 행과 열로 구분된 테이블을 생성할 때는 열에 해당하는 필드의 데이터 타입을 설정
- 필드의 데이터 타입을 문자열 또는 정수형 등으로 지정하여 데이터 타입을 명확하게 지정

참조 값 변경에 대한 조건 (FOREIGN KEY Constraints)
- 변경 제한
- 연쇄 cascade
- null 세팅
- default세팅
- 4가지 중 하나를 설정값으로 선택 가능하다.
[CONSTRAINT [symbol]] FOREIGN KEY
[index_name] (col_name, ...)
REFERENCES tbl_name (col_name,...)
[ON DELETE reference_option]
[ON UPDATE reference_option]
reference_option:
RESTRICT | CASCADE | SET NULL | NO ACTION | SET DEFAULTDML : insert , delete , select update
- 오라클 database의 명령어와 거의 유사하기 때문에 스킵합니다.
MySQL과 Oracle의 차이점
- 집합 연산 중에서 union 연산만 제공한다.
- 교집합과 차집합은 JOIN과 서브쿼리로 직접 만들어야 한다.
데이터 형태

합집합
- UNION : 중복 없이 가져오기
select emp_no from titles where title = 'Senior Staff'
union
select emp_no from titles where title = 'Staff'
order by emp_no;
- UNION ALL : 중복을 허용해서 가져오기
select emp_no from titles where title = 'Senior Staff'
union all
select emp_no from titles where title = 'Staff'
order by emp_no;
교집합
- Join으로 만든다
- A그룹(Staff) 에도 속하고 , B그룹(Senior Staff)에도 속하는 사원번호 가져오기
-- 따로 함수가 제공되지 않으므로 join 연산을 통해 만들어야 한다
select t1.emp_no
from titles t1 , titles t2
where t1.emp_no = t2.emp_no
and t1.title = 'Senior Staff'
and t2.title = 'Staff'
order by t1_emp_no;
차집합
- 서브쿼리로 만든다.
- A그룹(Staff) 에도 속하고 , B그룹(Senior Staff)에는 속하지 않는 사원번호 가져오기
-- 따로 함수가 제공되지 않으므로 서브 쿼리문을 통해 만들어야 한다.
select emp_no
from titles
where title = 'staff' and
enp_no not in(
select emp_no
from titles
where title = 'Senior Staff'
)
order by emp_no asc;