
내장 함수
- SQL의 함수는 DBMS가 제공하는 내장 함수와 사용자가 필요에 따라 직접 만드는 사용자 정의 함수로 나뉜다.
오라클 주요 내장 함수
숫자 함수
문자 함수
날짜 - 시간 함수
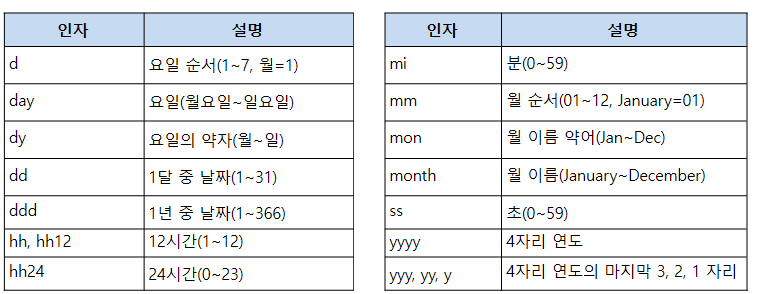
- datetime의 주요 인자
NULL 값 처리
- NULL값은 아직 지정되지 않은 값으로 비교 연산자로 비교가 불가능하다.
- NULL 값에 연산을 수행하면 결과가 NULL로 반환되기 때문에 집계함수를 사용할 때 주의해야 한다.
- 집계 함수 계산 시 NULL이 포함된 행은 집계에서 빠지게 된다.
NULL 확인 방법
- IS NULL , IS NOT NULL
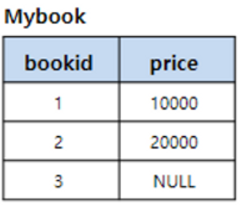
SELECT *
FROM Mybook
WHERE pice IS NULL;
NULL 값 처리
- NVL : NULL 값을 다른 값으로 대치하여 연산하거나 다른 값으로 출력
EX) 이름, 전화번호가 포함된 고객목록을 보이시오. 단, 전화번호가 없는 고객은 ‘연락처 없음’으로 표시한다.
SELECT name "이름", NVL(phone, '연락처없음') "전화번호"
FROM Customer;
ROWNUM
- 내장 함수는 아니지만 자주 사용되는 문법이다.
- 오라클 내부적으로 생성되는 가상 칼럼으로 SQL 조회 결과의 순번을 나타내며 자료의 일부분만 확인하여 처리할 때 유용함.
EX) 고객 목록에서 고객번호, 이름, 전화번호를 앞의 두 명만 보이시오.
SELECT ROWNUM “순번“, custid, name, phone
FROM Customer
WHERE ROWNUM <=2;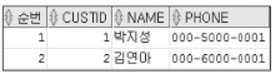
부속질의(SubQuery)
- join은 기본적으로 모든 경우의 수를 계산하는 cartesian product가 선행된다. 이 경우 연산을 위한 메모리와 연산시간이 너무 크기 때문에 subQuery가 발전하게 되었다.(일종의 튜닝, 성능 향상시키는 방식)
- 하나의 SQL 문 안에 다른 SQL 문이 중첩된 nested 질의를 말함.
- 다른 테이블에서 가져온 데이터로 현재 테이블에 있는 정보를 찾거나 가공할 때 사용함
- 보통 데이터가 대량일 때 데이터를 모두 합쳐서 연산하는 조인보다 필요한 데이터만 찾아서 공급해 주는 부속질의가 성능이 더 좋음
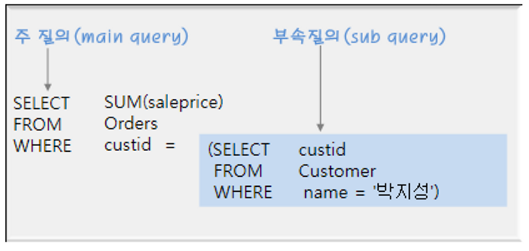
- 주질의(main query, 외부질의)와 부속질의(sub query, 내부질의)로 구성됨.
부속질의의 종류
- SQL 쿼리문의 문법을 맞추기 위해서는 SELECT, FROM , WHERE에 따라 subquery의 반환값을 알아야 한다.
스칼라 부속질의 - SELECT 부속질의
- 부속질의의 결과 값을 단일 행, 단일 열의 스칼라 값으로 반환한다.
- SELECT, UPDATE SET 절 등에 사용되며, 원칙적으로 스칼라 값이 들어갈 수 있는 모든 곳에 사용 가능하다.
- 주질의와 부속질의와의 관계는 상관/비상관 모두 가능함.
- SELECT절 뒤에는 일반적으로 속성명이 들어간다. 즉, SELECT 절에 오는 부속질의의 반환값이 scalar값이면 문제없이 작동한다.
EX) 마당서점의 고객별 판매액을 보이시오(고객 이름과 고객별 판매액을 출력)
SELECT ( SELECT name
FROM Customer cs
WHERE cs.custid=od.custid ) "name", SUM(saleprice) "total"
FROM Orders od
GROUP BY od.custid;
FROM 부속질의
- FROM절 뒤에는 일반적으로 테이블 명이 들어간다. 즉, FROM절에 오는 부속질의의 반환값이(결괏값) 2차원 배열이면 문제없이 작동한다.
- 테이블 이름 대신 인라인 뷰 부속질의를 사용하면 보통의 테이블과 같은 형태로 사용할 수 있음.
- 가상의 테이블인 뷰 형태로 제공되기 때문에 상관 부속질의로는 사용될 수 없음.
EX) 고객번호가 2 이하인 고객의 판매액을 보이시오(고객이름과 고객별 판매액 출력)
SELECT cs.name, SUM(od.saleprice) "total"
FROM (SELECT custid, name
FROM Customer
WHERE custid <= 2) cs,
Orders od
WHERE cs.custid=od.custid
GROUP BY cs.name;
WHERE 부속질의
- WHERE절 뒤에는 보통 데이터를 선택하는 조건 혹은 술어(predicate)와 같이 사용된다. 그렇기 때문에 술어에 따라 return 해야 하는 구조가 달라지기에 가장 어려운 부속질의 영역이다.
- 예를 들어 < 이면 부속질의는 scalar값이 반환되어야 하고, IN은 부속질의의 값이 벡터값(집합체)이 반환되어야 한다.
중첩질의 연산자의 종류
- 아래 두 예시로 보는 비교 연산자의 상관 서브질의와 비상관 서브질의의 차이.
- 비상관 서브질의 : 상수 값을 비교하는 경우이기 때문
- 상관 서브질의 : 고객별 평균 주문 금액을 비교해야 하기 때문
비상관 서브질의 EX) 평균 주문금액 이하의 주문에 대해서 주문번호와 금액을 보이시오.
SELECT orderid, saleprice
FROM Orders
WHERE saleprice <= (SELECT AVG(saleprice)
FROM Orders);
상관 서브질의 EX) 각 고객의 평균 주문금액보다 큰 금액의 주문 내역에 대해서 주문번호, 고객번호, 금액을 보이시오.
SELECT orderid, custid, saleprice
FROM Orders od
WHERE saleprice > (SELECT AVG(saleprice)
FROM Orders so
WHERE od.custid=so.custid);
- IN , NOT IN : 주질의 속성 값이 부속질의에서 제공한 결과 집합에 있는지 확인하는 역할을 함. IN의 특성상 다중 행을 가질 수 있으며 하나라도 참인 것이 있으면 참이 된다.(NOT IN은 값이 존재하지 않아야 참이 된다)
EX) 대한민국에 거주하는 고객에게 판매한 도서의 총판매액을 구하시오.
SELECT SUM(saleprice) "total"
FROM Orders
WHERE custid IN (SELECT custid
FROM Customer
WHERE address LIKE '%대한민국%');
-- 출력결과 total :46000- ALL : 모두
- SOME(ANY) : 어떠한(최소한 하나라도)
EX) 3번 고객이 주문한 도서의 최고 금액보다 더 비싼 도서를 구입한 주문의 주문번호와 금액을 보이시오.
SELECT orderid, saleprice
FROM Orders
WHERE saleprice > ALL (SELECT saleprice
FROM Orders
WHERE custid='3');
subquery 사용 규칙(중요)
- 서브쿼리(subquery)란 하나의 SQL문 안에 포함되어 있는 또 다른 SQL문을 말한다.
- 서브쿼리는 다음과 같이 메인쿼리가 서브쿼리를 포함하는 종속적인 관계에 놓여있다.
- 서브쿼리는 메인쿼리의 칼럼을 모두 사용할 수 있음
- 메인쿼리는 서브쿼리의 칼럼을 사용할 수 없음
- 서브쿼리 칼럼을 표시해야 한다면 스칼라 서브쿼리(SELCT(SELECT~~)), 함수 등을 사용
- 서브쿼리는 서브쿼리 레벨과는 상관없이 항상 메인쿼리 레벨로 결과 집합이 생성
- 서브쿼리는 괄호로 감싸서 사용
- 서브쿼리는 단일행 또는 복수행 비교연산자와 함께 사용 가능
- 서브쿼리에서는 ORDER BY 절을 사용하지 못하고, 메인쿼리 마지막 문장에 사용 가능
서브쿼리가 SQL 문에서 사용 가능한 곳
- SELECT절, FROM절, WHERE절, HAVING절, ORDER BY절, INSERT문의 VALUES절, UPDATE문의 SET절
- 서브쿼리의 종류는 동작하는 방식이나 반환되는 데이터의 형태에 따라 다음과 같이 두 분류로 나눌 수 있다.
- 비연관 서브쿼리 : 서브쿼리가 메인쿼리 칼럼을 가지고 있지 않는 형태의 서브쿼리이다. 메인쿼리에 값(서브쿼리가 실행된 결과를 제공하기 위한 목적으로 주로 사용한다.
- 연관 서브쿼리 : 서브쿼리가 메인쿼리 칼럼을 가지고 있는 형태의 서브쿼리이다. 일반적으로 메인쿼리가 먼저 수행되어 읽힌 데이터를 서브쿼리에서 조건이 맞는지 확인하고자 할 때 주로 사용된다.
- 서브쿼리는 메인쿼리 안에 포함된 종속적인 관계이기 때문에 논리적인 실행스순서는 항상 메인쿼리에서 읽힌 데이터에 대해 서브쿼리에서 해당 조건이 만족하는지를 확인하는 방식으로 수행되어야 한다. 그러나 실제 서브쿼리의 실행순서는 상황에 다라 달라질 수 있다.
뷰(VIEW)
- 뷰는 하나 이상의 테이블을 합하여 만든 가상의 테이블.
- server - DBClient 사이에 또는 운영체제와 process 사이에 Reading은 동시에 수행 가능하지만 Writing기능은 동시에 불가능하다.
- commit 명령을 내리지 않으면 실제 물리영역에 적용되지 않기 때문에 commit을 마지막에 넣어왔던 것임.
- commit이 수행되면 취소할 수 없음. 반대로 생각하면 commit만 하지 않으면 무슨 짓을 하던 되돌릴 수 있는 것.
- VIEW도 가상의 테이블이기 때문에
장점
- 편리성 및 재사용성 : 자주 사용되는 복잡한 질의를 뷰로 미리 정의해 놓을 수 있음. → 복잡한 질의를 간단히 작성
- EX) 카티전 프로덕트의 경우 오래 걸리기 때문에 미리 해두고, 뷰에 저장해 두는 방식으로 미리 연산된 뷰를 가져와 시간을 단축할 수 있음.
- 보안성 : 각 사용자별로 필요한 데이터만 선별하여 보여줄 수 있음. 중요한 질의의 경우 질의 내용을 암호화할 수 있음 → 개인정보(주민번호)나 급여, 건강 같은 민감한 정보를 제외한 테이블을 만들어 사용
- 독립성 제공 : 미리 정의된 뷰를 일반 테이블처럼 사용할 수 있기 때문에 편리함. 또 사용자가 필요한 정보만 요구에 맞게 가공하여 뷰로 만들어 쓸 수 있음. → 원본테이블이 구조가 변하여도 응용에 영향을 주지 않도록 하는 논리적 독립성 제공
EX) 주소에 ‘대한민국’을 포함하는 고객들로 구성된 뷰를 만들고 조회하시오.
단, 뷰의 이름은 vw_Customer로 한다.
CREATE VIEW vw_Customer
AS SELECT *
FROM Customer
WHERE address LIKE '%대한민국%';
EX) Orders 테이블에 고객이름과 도서이름을 바로 확인할 수 있는 뷰를 생성한 후, ‘김연아’ 고객이 구입한 도서의 주문번호, 도서이름, 주문액을 보이시오.
CREATE VIEW vw_Orders (orderid, custid, name, bookid, bookname, saleprice, orderdate)
AS SELECT od.orderid, od.custid, cs.name,
od.bookid, bk.bookname, od.saleprice, od.orderdate
FROM Orders od, Customer cs, Book bk
WHERE od.custid =cs.custid AND od.bookid =bk.bookid;
뷰의 수정
EX) 위에서 생성한 vw_Customer는 주소가 대한민국인 고객을 보여준다. 이 뷰를 영국을 주소로 가진 고객으로 변경하시오. phone 속성은 필요 없으므로 포함시키지 마시오.
CREATE OR REPLACE VIEW vw_Customer (custid, name, address)
AS SELECT custid, name, address
FROM Customer
WHERE address LIKE '%영국%';
뷰의 삭제
EX) 앞서 생성한 뷰 vw_Custoemer를 삭제하라.
DROP VIEW vw_Customer인덱스
- 데이터베이스에서는 저장소의 탐색시간을 줄이는 것이 중요함. Oracle에서는 index로 이를 해결하고자 함.
- index(데이터를 저장할 때 비선형자료구조인 Btree를 사용)
데이터베이스의 물리적 저장
DBMS와 파일
- 실제 데이터가 저장되는 곳은 보조기억장치이다.
- 하드디스크, SSD, USB 메모리 등
- 요즘은 클라우드 서비스와 연동하기도 한다.
오라클의 내부 구조
- 데이터 파일
- 운영체제상에 물리적으로 존재
- 사용자 데이터와 개체를 저장
- 테이블과 인덱스로 구성.
- 온라인 리두 로그
- 데이터의 모든 변경사항을 기록
- 데이터베이스 복구에 사용되는 로그 정보 저장
- 최소 두 개의 온라인 리두 로그 파일 그룹을 가짐
- 컨트롤 파일
- 오라클이 필요로 하는 다른 파일들(데이터 파일, 로그 파일 등)의 위치 정보를 저장
- 데이터베이스 구조 등의 변경사항이 있을 때 자동으로 업데이트됨
- 오라클 DB의 마운트, 오픈의 필수 파일
- 복구 시 동기화 정보 저장
인덱스와 B-tree
- 인덱스란 도서의 색인이나 사전과 같이 데이터를 쉽고 빠르게 찾을 수 있도록 만든 데이터 구조이다.
인덱스의 특징
- 물리적인 데이터 테이블에는 sequence 순서대로 저장되지 않고, 각자 저장되어 있지만 인덱스는 sequence 순서대로 만들어 논리적으로 같은 table끼리 묶어서 처리하는 방식이다. (Index는 가상의 자료구조이다)
- 인덱스는 테이블에서 한 개 이상의 속성을 이용하여 생성함.
- 빠른 검색과 함께 효율적인 레코드 접근이 가능함.
- 순서대로 정렬된 속성과 데이터의 위치만 보유하므로 테이블보다 작은 공간을 차지함.
- 저장된 값들은 테이블의 부분집합이 됨.
- 일반적으로 B-tree 형태의 구조를 가짐.
- 데이터의 수정, 삭제 등의 변경이 발생하면 인덱스의 재구성이 필요함.
오라클 인덱스 예시
인덱스 생성 시 고려사항
- 오라클의 경우 B tree 외에도 Index Organizer Table, Bitmap Index, Function- Base Index 인덱스 방식이 존재한다.
- 인덱스는 WHERE 절에 자주 사용되는 속성이어야 함.
- 인덱스는 조인에 자주 사용되는 속성이어야 함.
- 단일 테이블에 인덱스가 많으면 속도가 느려질 수 있음.(테이블 당 4~5개 정도 권장)
- 속성이 가공되는 경우 사용하지 않음.
- 속성의 선택도가 낮을 때 유리함(속성의 모든 값이 다른 경우).
인덱스 생성
CREATE [REVERSE]┃[UNIQUE] INDEX 인덱스이름]
ON 테이블이름 (칼럼 [ASC┃DESC] [{, 컬럼 [ASC | DESC]} …])[;]
EX) Book 테이블의 bookname 열을 대상으로 비 클러스터 인덱스 ix_Book을 생성하라
Create INDEX ix_Book
ON Book(bookname);인덱스 재구성
ALTER [REVERSE] [UNIQUE] INDEX 인덱스이름
[ON {ONLY} 테이블이름 {칼럼이름 [{, 컬럼이름 } …])] REBUILD [;]
EX) 인덱스 ix_Book을 재생성하시오.
ALTER INDEX ix_Book REBUILD;인덱스 삭제
DROP INDEX 인덱스이름
EX) 인덱스 ix_Book을 삭제하시오.
DROP INDEX ix_Book;'Back > DataBase이론' 카테고리의 다른 글
| 5장 데이터베이스 프로그래밍 - 2 (0) | 2023.03.27 |
|---|---|
| 5장 데이터베이스 프로그래밍 - 1 (0) | 2023.03.27 |
| 3장 SQL 기초 (0) | 2023.03.23 |
| 2장 관계형 데이터베이스 - 2 (0) | 2023.03.23 |
| 2장 관계 데이터 모델 -1 (0) | 2023.03.23 |